1. 引言
ChatGPT、LLaMa、Bard 等大语言模型(LLMs)取得了非常巨大突破,迅速在公众领域流行起来。LLMs所展现的强大文本生产能力让用户惊叹不已,属于划时代的产品。这些模型拥有数十亿甚至数千亿个参数,因而这些模型通常的部署和维护成本都惊人的高昂。这类大模型的的训练和推理都需要大量的计算资源和内存资源,企业需要投入海量的基础设施成本(不管是云服务还是自建机房都非常贵),来保证大模型能够稳定提供服务。
那么有没有办法花小钱办大事呢?
当然有。
本文旨在提供一些策略、提示和技巧,您可以在部署基础架构时应用这些策略、提示和技巧来优化基础架构。我们将重点探讨这些内容:
- 大模型部署与应用时将会面临的基础架构挑战
- 如何降低大模型部署与应用的成本
- 其他的一些有用的策略
2. 大模型部署与应用的挑战
LLMs遵循规模效应,也就是说参数越大,效果越好。因此它们一般需要海量GPU计算资源才能获得最佳性能。通常会面临以下的挑战:
2.1 高计算量
部署 LLM 是一个充满挑战的任务,因为它们需要大量计算资源来执行推理,尤其是模型用于实时应用程序(例如聊天机器人或虚拟助手)为甚。
以 ChatGPT 为例,大多数情况下它能够在几秒钟内处理和响应用户查询。尤其是繁忙时段瞬间涌入海量用户会使得推理时间会变长。还有其他因素可能会延迟推理,例如问题的复杂性、生成响应所需的信息量等等。总而言之,大模型要提供实时服务,它必须能够实现高吞吐量和低延迟。
2.2 大存储量
由于模型参数规模从数百万到数千亿,LLM 的存储也是一个充满挑战的问题。由于大模型规模太大,所以无法直接将整个模型存储在单个存储设备。
例如,OpenAI 的 GPT-3 模型有 1750亿 个参数,仅其权重参数存储就需要超过 300GB 的存储空间。
此外,它还需要至少具有 16GB 显存的 GPU 才能高效运行(意味着起码是T4级别以上的N卡)。
因此,在单个设备上存储和运行如此大的模型对于许多用户场景来说是不切实际的。整体来说,
LLM 的存储容量存在三个主要问题:
- 内存限制 : LLMs需要大量内存,因为它们要处理大量信息。部署此类模型的一种方法是使用分布式系统,模型分布在多个服务器节点上。这种系统允许将推理任务切分分配到多台服务器上,实现负载均衡和推理加速。这类系统通常架构都比较复杂,需要大量的专业知识来设置和维护这些分布式机器。模型越大,需要的服务器就越多,这也增加了部署成本。还有一种复杂的场景就是,如何将大模型部署在手机等内存较小的设备上。
- 模型规模 : 如果输入查询又长又复杂,即便运行在大内存显卡上的模型推理过程中也很容易耗尽内存。即使对于 LLM 的基本推理,也需要多个加速器或多节点计算集群(例如多个 Kubernetes Pod)。
- 可扩展性 : 大模型通常使用模型并行化(MP)进行扩展,这涉及将模型分成更小的部分并将其分布在多台机器上。每台机器处理模型的不同部分,并将结果组合起来产生最终输出。该技术有助于大模型训练,但也需要仔细考虑机器之间的通信开销。
2.3 网络带宽
如上所述,LLM 必须使用 MP 进行扩展。但我们发现的问题是,模型并行化 在单节点集群中是有较好效果,但在多节点集群中,由于网络通讯开销,导致推理效率不高。
2.4 成本与能耗
如上文所述,部署和使用 LLM 的成本可能很高,包括硬件和基础设施的成本,尤其是在推理过程中使用 GPU 或 TPU 等资源来实现低延迟和高吞吐量时。对小公司和个人来说,这是一个非常大的挑战。
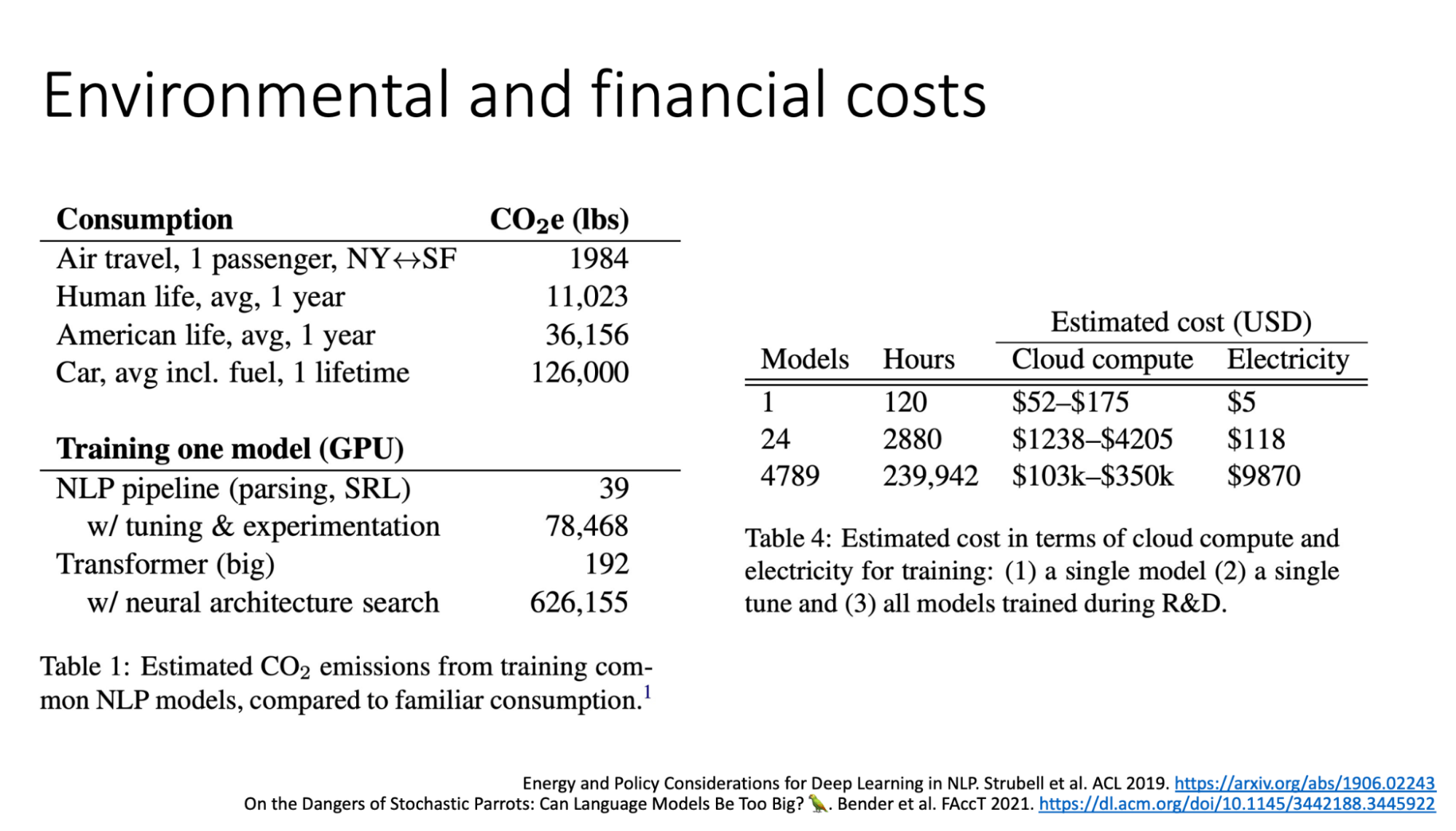
LLMs的费用估算以及碳足迹| 来源
根据 NVIDIA的说法,80-90% 的机器学习工作负载是推理带来的。同样,根据 AWS 的数据,推理占云中机器学习需求的 90%。
在22年12月份,chatGPT 的运行成本约为每天 100,000 美元或每月 300 万美元。随着ChatGPT的大获成功,GPT-4的推出等,估计现在(23年7月)估计要比当时(22年12月)高出一个数量级了
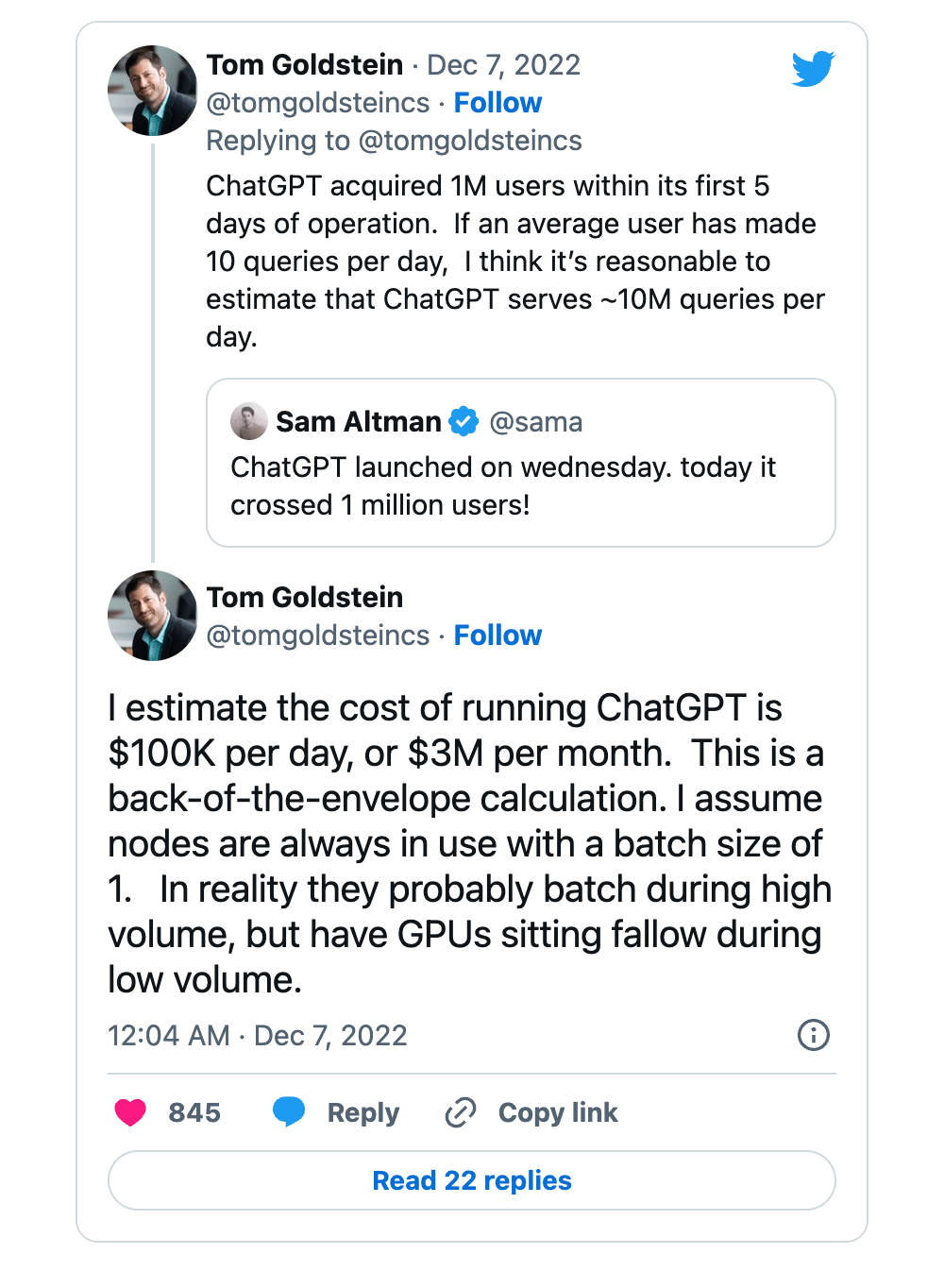
关于ChatGPT成本的推文 | 来源
3. 优化大模型基础设施成本的策略
在本节中,我们将探讨并讨论前一节中讨论的挑战的可能解决方案和技术。
首先以AWS作为云供应商,来实现大模型推理的工作流作为例子: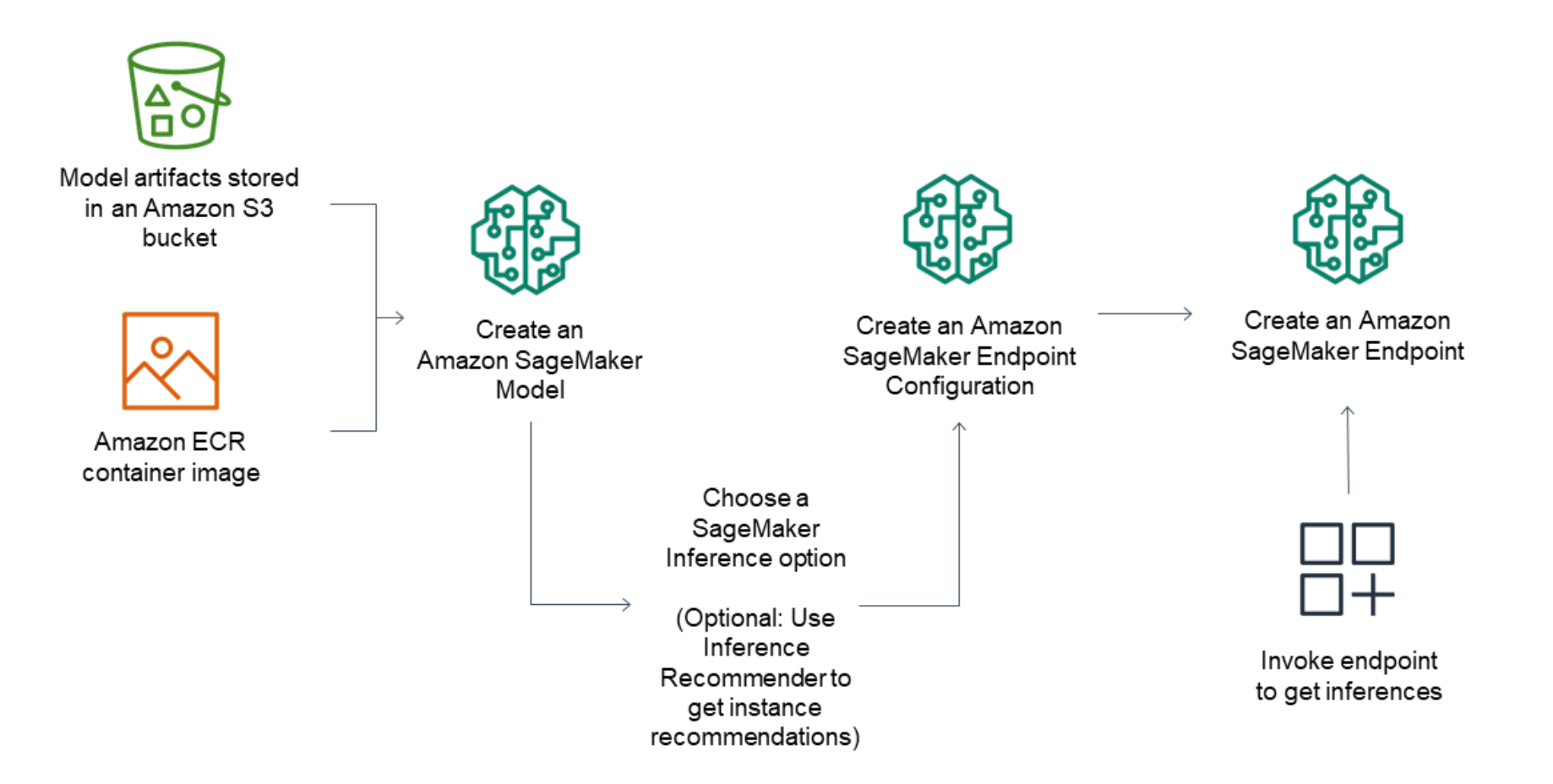
AWS上的大模型推理的工作流 | 来源
您可以按照以下的步骤尽可能高效地部署大模型。
3.1 云计算预算评估与规划
使用云计算服务可以提供动态、按需使用包括CPU,GPU,TPU在内的各种强大的计算资源。云计算服务灵活且可扩展性强,但是在使用云服务的时候,首先你需要为自己的项目制定一个项目预算,这样能够让你的基础设施投入更加合理可控。
云服务提供商如AWS、Azure和google cloud提供了一系列部署LLM的产品,包括虚拟机、容器和无服务器计算。但是尽管如此,建议还是需要根据自己业务情况进行研究和计算,选择更加合理的云服务解决方案。例如,你必须核实以下三个方面信息:
- 模型尺寸
- 关于要使用的硬件的详情
- 合理的推理产品方案
根据上述三个方面的信息,可以计算出你需要多少加速计算能力,从而规划并执行适合你自身业务的大模型部署。
3.1.1 计算模型大小
您可以根据以下表格,折算自己模型大概需要多少多少FLOPs算力,从而确定要在云平台上找到相相应的GPU。

预估计算FLOPs
另外这个工具也可以帮你计算模型在训练和推理过程中所需的FLOPs。

3.1.2 选择合适的硬件
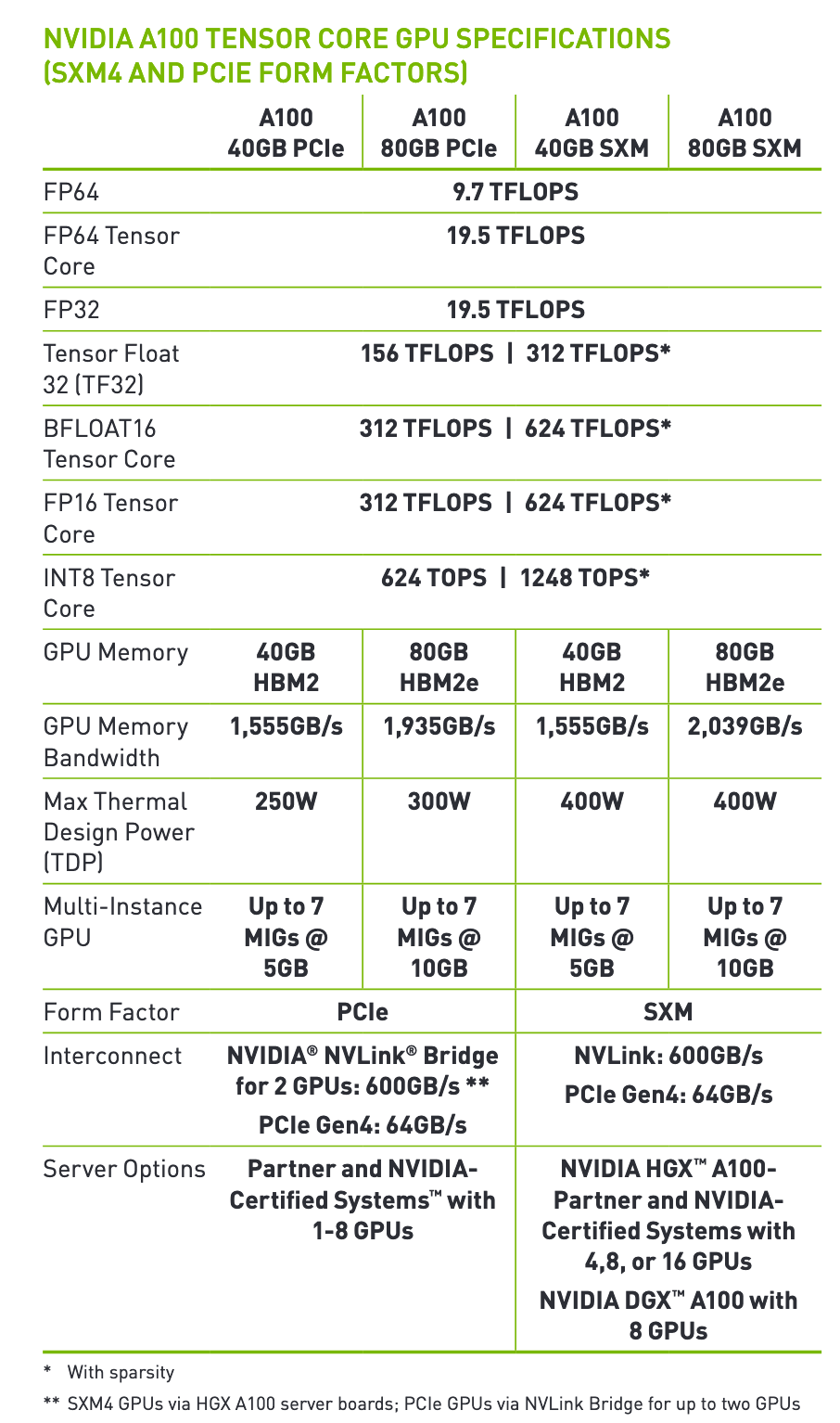
当你计算出所需的FLOPs,就可以继续选择GPU。确保你了解GPU所提供的功能。例如,查看下面的图片以了解情况。可以参考以下A100的GPU规格,选择符合预算的显卡。最新的H100芯片可以访问这个链接
3.1.3 选择正确的推理产品
Amazon SageMaker是一个机器学习云服务产品,提供多种推理选项,以适应不同的工作负载。例如,如果您需要:
实时推理, 适用于低延迟或高吞吐量的在线推理,支持最大6 MB的负载大小和60秒的处理时间。
无服务器推理,适用于间歇性或不可预测的流量模式,并支持高达4 MB的负载大小和60秒的处理时间。在无服务器推理中,模型根据流量弹性伸缩,自动扩容或者缩容。
批量处理 ,适用于大型数据集的离线处理,适合以GB为单位的负载大小和以天为单位的处理时间的场景。
异步推理 ,适用于排队具有大负载和长处理时间的请求,支持最大1 GB的负载和最长一小时的处理时间. 。同样支持弹性伸缩。
为了更好地理解并满足您的要求,请查看下方的图片。

当满足以上所有要点时,您可以将模型部署在任何云服务上。
3.1.4 小结:
- 1 设定预算
- 2 计算模型的大小
- 3 计算模型所需的FLOPs
- 4 找到合适的GPU
- 5 选择适当的推理类型
- 6 研究各个云计算平台提供的定价
- 7 找到适合您需求和预算的服务
- 8 部署
3.2 优化模型以提供服务
在上一节中,我们讨论了不同规模的LLM的规模如何部署。如果当我们的模型过大时,可以采用模型编译、模型压缩和模型分片等策略。这些技术可以在保持准确性的同时减小模型的大小,部署起来更容易,与之同时会显著降低相关费用。
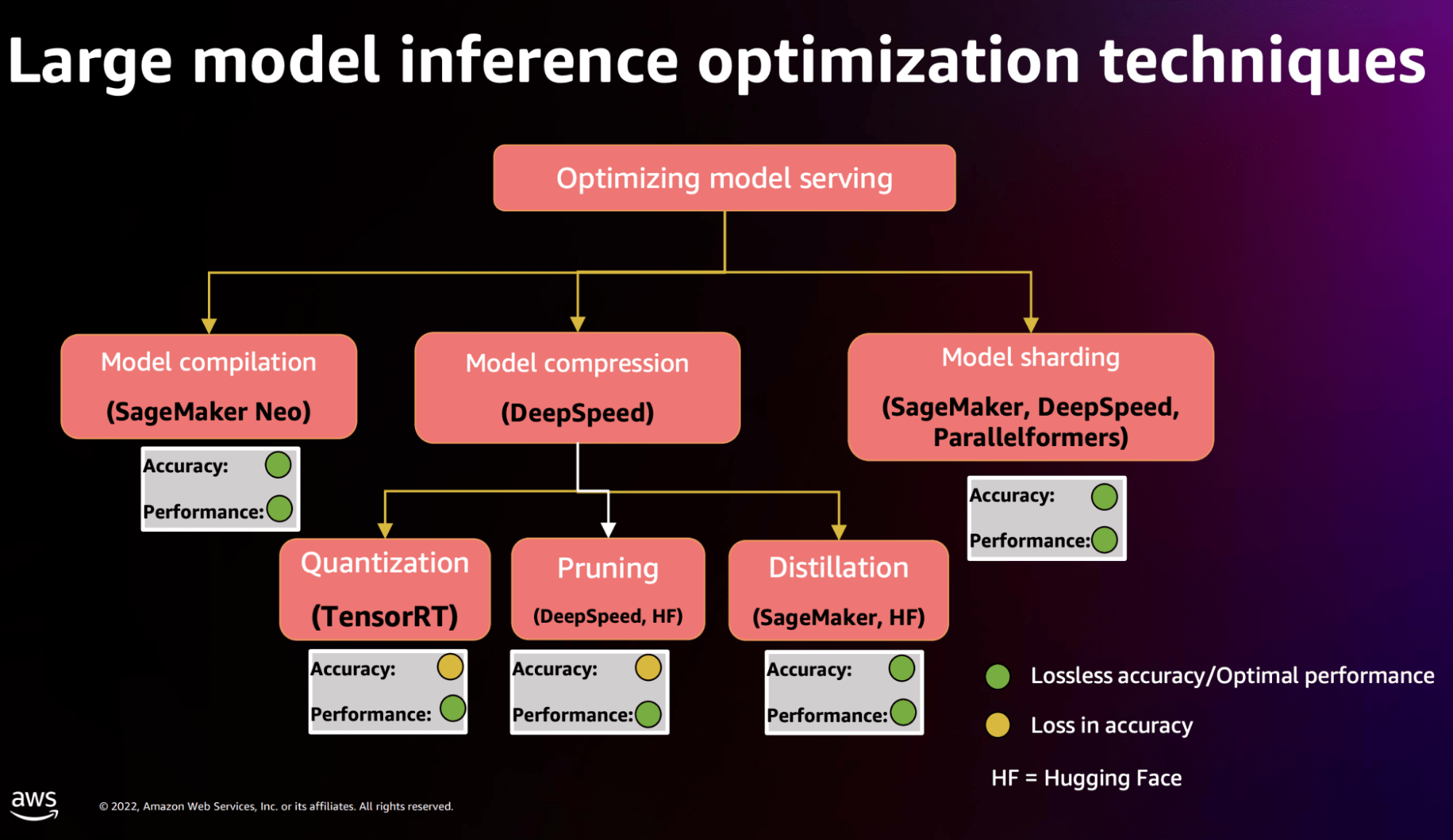
3.2.1 模型压缩
模型压缩的目标是通过利用硬件特定优化,如减少内存占用、改善计算并行性和减少延迟,来提高LLM推理的性能和效率。模型压缩能够帮助你尝试不同的技术组合,为各种任务设定性能基准,并找到适合预算的方案。模型压缩一般涉及几个步骤:
- 计算图优化(Graph optimization): 使用剪枝和量化等优化技术对高级LLM图进行转换和优化,以降低模型的计算复杂度和内存占用。这样,模型变得更小,同时保持其准确性。
- 硬件感知优化(Hardware-specific optimization): 在优化过的LLM计算图基础上进一步实现硬件优化。Amazon Sagemaker为各种流行的ML框架提供了基于硬件优化的模型服务容器以及SDK,包括XGBoost,scikit-learn,PyTorch,TensorFlow和Apache MXNet。
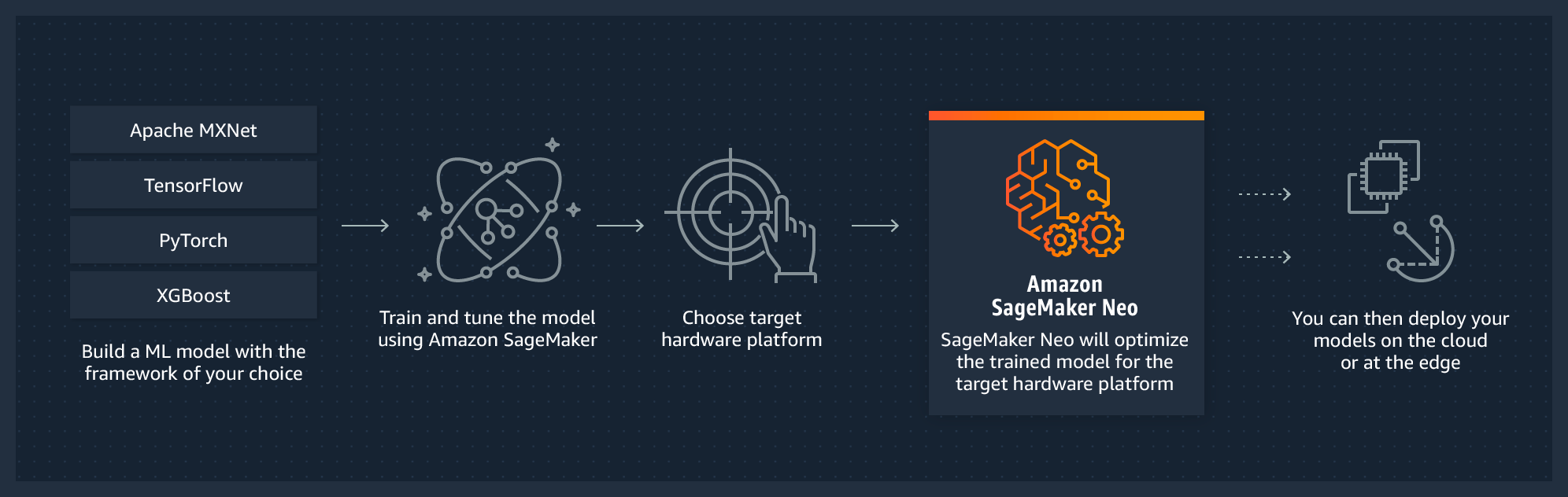
以下是一些必须了解的模型压缩技术。
3.2.1.1 模型量化
模型量化(MQ)是一种减少机器学习模型大小和计算复杂性的技术。在模型量化中,我们将模型的权重和激活函数从浮点数(例如32位)转换为更小的数据类型(例如8位整数)。这样做的原因是,更小的数据类型需要更少的存储空间和计算资源。
这个过程可以类比为我们在生活中的经验。比如,你有一张非常详细的地图,这张地图上的每一条街道、每一棵树都画得非常清楚。但是,这张地图非常大,你无法把它放进口袋里。于是,你决定制作一张简化版的地图,只标注主要的街道和地标。这样,你的地图就变小了,可以放进口袋里,但是它仍然包含了你需要的主要信息。
在模型量化中,我们也是这样做的。我们将模型的权重和激活函数简化,使其变小,但仍然尽可能地保留了原始模型的信息。
然而,这种简化过程确实可能会导致一些信息的丢失,这就是所谓的量化误差。这种误差可能会对模型的精度产生影响。但是,通过一些技术,如重新校准(re-calibration)和量化感知训练(quantization-aware training),我们可以在一定程度上减小这种影响。这些技术可以帮助模型在量化过程中适应信息的丢失,从而在减小模型大小的同时,尽可能地保持模型的精度。
PyTorch 提供了模型量化的能力。PyTorch 提供了一套完整的量化工具,包括动态量化(Dynamic Quantization)、静态量化(Static Quantization)以及量化感知训练(Quantization Aware Training)。
动态量化:这种方法只量化模型的权重,而不量化激活。这种方法的优点是实现简单,不需要对模型进行任何修改,但可能不如其他方法减少模型大小和提高性能。
静态量化:也称为(Post-training quantization)。这种方法在训练后进行,它包括权重和激活的量化,以及模型的重校准。这种方法可以进一步减小模型大小和提高性能,但需要更多的步骤来实现。
量化感知训练:也称为(Hybrid quantization). 这种方法在训练过程中引入量化,使模型能够适应量化带来的误差。这种方法可以在减小模型大小和提高性能的同时,保持或提高模型的精度。
PyTorch 提供了一系列的 API 和教程来帮助开发者实现模型量化。这些工具可以帮助你将模型量化,使其更适合在资源有限的设备上运行。
虽然模型量化有很多优点,如减小模型大小、减少计算需求、提高推理速度等,但是它也有一些潜在的缺点:
精度下降:量化过程可能会导致一些信息的丢失,这可能会对模型的精度产生影响。虽然有一些技术可以减小这种影响,但在某些情况下,精度的下降可能是无法避免的。
实现复杂:实现模型量化可能需要对模型进行一些修改,这可能会增加实现的复杂性。例如,你可能需要进行量化感知训练,或者对模型进行重校准。
硬件兼容性:虽然模型量化可以帮助模型在资源有限的设备上运行,但并非所有的硬件都支持量化模型。在某些硬件上,运行量化模型可能不会带来预期的性能提升。
模型兼容性:并非所有的模型都适合量化。某些模型可能在量化后的性能下降较大,或者无法进行有效的量化。
因此,虽然模型量化是一种强大的工具,但在使用它时,你需要考虑到这些潜在的问题,并根据你的具体需求和条件来决定是否使用模型量化。
3.2.1.2 模型剪枝
模型剪枝(Model Pruning)是一种优化技术,它的目标是通过移除模型中的一部分参数(例如神经网络中的神经元或连接)来减小模型的大小和计算需求,同时尽可能地保持模型的性能。
模型剪枝的基本思想是,模型中的一些参数对模型的性能贡献很小,因此可以安全地移除它们。例如,在神经网络中,我们可以移除那些权重很小的连接,因为它们对模型的输出影响很小。
模型剪枝有很多种方法,包括:
权重剪枝:这种方法移除那些权重值小于某个阈值的连接。这种方法的优点是实现简单,但可能会导致模型的结构变得不规则,从而影响硬件的优化。
单位剪枝:这种方法移除整个神经元或者卷积核。这种方法可以保持模型的结构规则,从而更适合硬件的优化,但可能会对模型的性能产生更大的影响。
结构剪枝:这种方法移除模型中的一部分结构,例如卷积层或者全连接层。这种方法可以大大减小模型的大小,但需要更复杂的算法来确定应该移除哪些结构。
稀疏剪枝:这种方法试图在保持模型性能的同时,最大化模型的稀疏性。这通常通过一些优化算法来实现,例如L1正则化。
动态剪枝:这种方法在模型的训练过程中动态地进行剪枝。这种方法的优点是可以根据模型的训练情况来调整剪枝的策略,但实现起来可能比较复杂。
下面是一个使用 PyTorch 进行权重剪枝的简单例子:
1 | import torch |
在这个例子中,首先创建了一个简单的线性模型。然后,使用 prune.l1_unstructured 方法进行剪枝,剪掉了 30% 的权重。最后,打印出了剪枝后的权重。
这只是一个非常简单的例子,实际的剪枝过程可能会更复杂。例如,可能需要在剪枝后重新训练模型,以恢复模型的性能,也可能需要使用更复杂的剪枝方法,例如单位剪枝或结构剪枝。
你可以通过PyTorch的这个Colab笔记本来更好地了解MP。
3.2.1.3 模型蒸馏
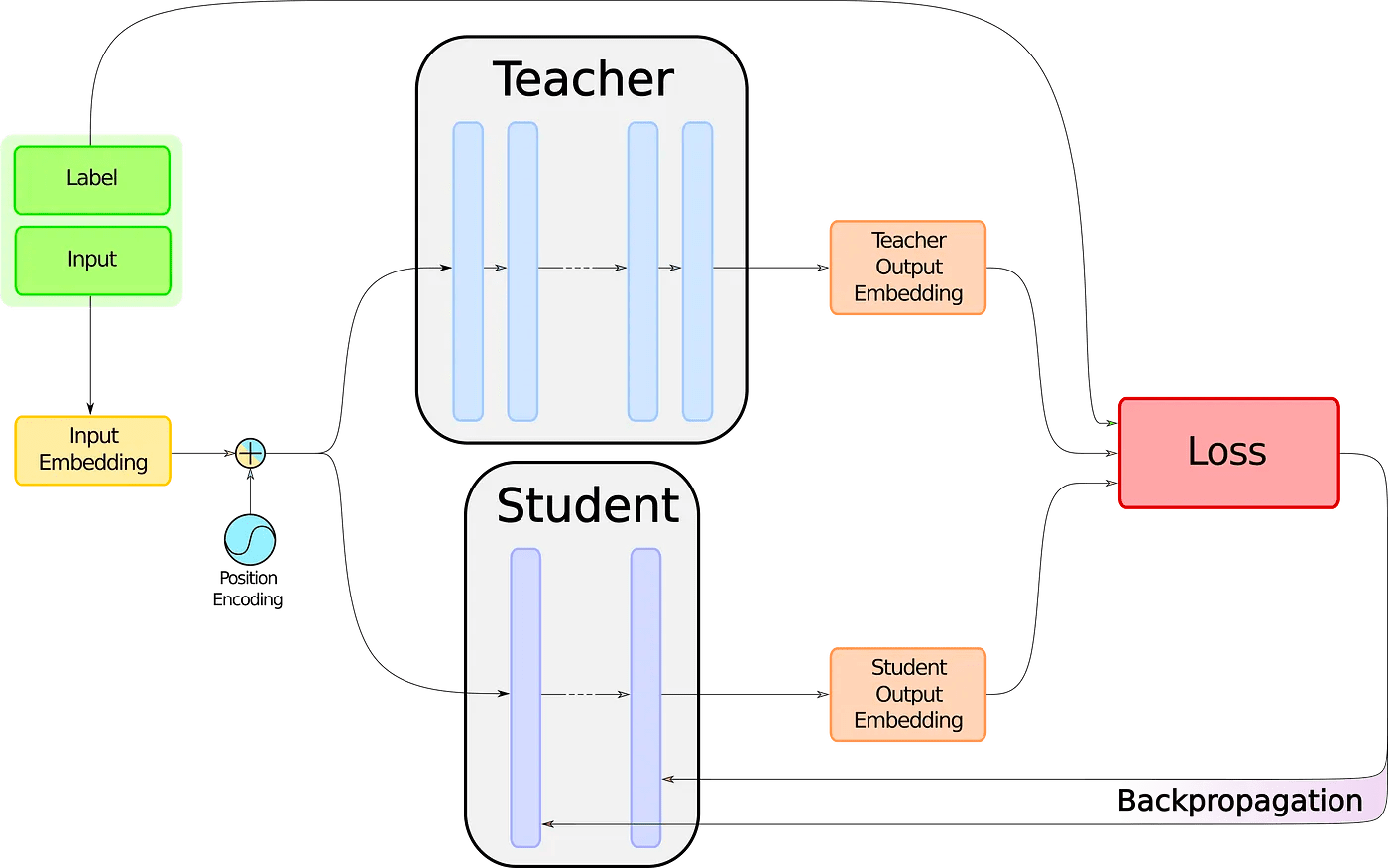
模型蒸馏是一种模型压缩技术,它的主要步骤如下:
训练教师模型:首先,需要训练一个大的模型,这个模型通常被称为教师模型。教师模型通常是一个深度的、复杂的模型,它可以在训练数据上达到很高的性能。
获取教师模型的输出:然后,使用教师模型对训练数据进行预测,获取教师模型的输出。这些输出通常包括类别的预测,以及预测的概率或者置信度。
训练学生模型:接着,训练一个小的模型,这个模型通常被称为学生模型。学生模型通常是一个浅度的、简单的模型,它的目标是学习教师模型的输出。在训练过程中,不仅要最小化学生模型的输出和数据的标签之间的差异,还要最小化学生模型的输出和教师模型的输出之间的差异。
评估学生模型:最后,评估学生模型的性能。如果学生模型的性能达到了我们的要求,那么就可以使用学生模型来替代教师模型了。
以BERT为例,模型蒸馏工作流程请参见下方的图片。
模型蒸馏的具体方法有很多种,以下是一些常见的方法:
软标签蒸馏:这是最常见的模型蒸馏方法,也是模型蒸馏的基础。在这种方法中,教师模型的输出(通常是概率分布)被用作学生模型的目标。这种方法可以帮助学生模型学习到教师模型的知识,包括类别之间的关系和对于某些难以分类的样本的不确定性。
特征蒸馏:在这种方法中,我们不仅要让学生模型学习到教师模型的输出,还要让学生模型学习到教师模型的中间特征。这种方法可以帮助学生模型学习到更深层次的知识,从而提高模型的性能。
关系蒸馏:在这种方法中,我们让学生模型学习到教师模型的输出之间的关系。例如,我们可以让学生模型学习到教师模型对于一对样本的相对预测。这种方法可以帮助学生模型学习到更复杂的知识,从而提高模型的性能。
注意力蒸馏:在这种方法中,我们让学生模型学习到教师模型的注意力分布。这种方法可以帮助学生模型学习到教师模型的注意力机制,从而提高模型的性能。
我们用一个使用 PyTorch 实现模型蒸馏的代码示例来加深理解。
在这个例子中,我们首先创建了一个教师模型和一个学生模型,然后使用自定义的损失函数进行模型蒸馏。
1 | import torch |
在这个例子中,首先创建了一个教师模型和一个学生模型。然后,定义了损失函数和优化器。还定义了蒸馏的温度和权重,这两个参数用于控制蒸馏的强度。
在训练过程中,首先计算教师模型的输出,然后将这些输出转换为概率分布。接着,我们计算学生模型的输出,然后将这些输出转换为概率分布。然后,计算两种损失:一种是学生模型的输出和数据标签之间的损失,另一种是学生模型的输出和教师模型的输出之间的损失。这两种损失的权重由 alpha 参数来控制。最后,进行反向传播和优化。
可以在这个链接中找到完整的代码和更详细的解释:Towards Data Science: Introduction to PyTorch Model Compression Through Teacher-Student Knowledge Distillation。
3.2.2 LLM的硬件优化
选择适合LLM需求的硬件:大型语言模型(LLMs)通常需要大量的计算资源和存储空间。例如,如果我们模型是一个大型的Transformer模型,需要具有大量RAM和多个GPU的高性能服务器。另一方面,如果我们模型是一个小型的RNN模型,可能只需要一个具有适量RAM和一个GPU的普通服务器。选择合适的硬件可以确保我们模型能够有效地运行,同时避免浪费资源。
利用专用硬件:专用硬件,如TPU(张量处理单元),是专门为深度学习任务设计的硬件加速器。TPU在处理张量运算(这是深度学习模型的基础)方面非常高效。例如,Google的BERT模型就是在TPU上训练的。此外,推理时可以考虑使用加速线性代数(XLA)。XLA是一种优化编译器,可以将TensorFlow的计算图优化为高效的机器代码,从而提高性能。
使用优化的库:优化的库,如TensorFlow、PyTorch或JAX,可以利用硬件特性来加速计算。例如,TensorFlow可以自动地将计算任务分配到多个GPU上,从而提高性能。PyTorch则提供了一种动态计算图的特性,可以更灵活地构建和修改模型。JAX则提供了一种函数转换的特性,可以更容易地实现复杂的优化算法。
调整批次大小:在推理过程中,适当调整批次大小可以最大化硬件利用率并提高推理速度。例如,如果GPU有足够的内存,可以增大批次大小,这样可以让GPU同时处理更多的数据,从而提高性能。但是,如果批次大小太大,可能会导致内存溢出。因此,我们需要根据硬件条件和模型需求来调整批次大小。
持续监控和优化:在部署过程中,需要持续监控模型的性能,包括推理速度、内存使用情况、GPU利用率等。如果发现性能有问题,可能需要调整硬件配置,例如增加RAM、增加GPU、升级存储设备等。也可能需要优化模型或代码,例如减小模型大小、优化计算图、减少数据传输等。
3.3 成本效益(Cost Efficient,CE) 的可扩展性
以下是我们可以在控制成本的同时扩展大型自然语言处理模型的方法:
选择合适的推理选项:例如,我们可以选择使用AWS SageMaker或Google Cloud AI Platform,这些服务可以根据需求动态分配资源,从而在需求较少时降低部署成本。
优化推理性能:我们可以通过使用硬件加速,如GPU或TPU,以及优化推理代码来提高推理性能。例如,我们可以使用TensorRT或OpenVINO这样的库来优化我们的模型,使其能够更有效地在GPU或TPU上运行。
使用缓存:如果我们的模型需要处理大量的重复请求,我们可以使用缓存来提高性能和降低成本。例如,我们可以使用Redis或Memcached这样的缓存服务来存储我们的模型的推理结果。当我们收到一个相同的请求时,我们可以直接从缓存中获取结果,而不需要再次运行模型。这样可以显著减少我们的计算需求,从而降低成本。
4. 结论
我们总结一下全文的流程
- 设定预算:明确我们的财务预算,以便在部署大型语言模型时做出明智的决策。
- 计算模型大小:理解我们的模型的规模,以便选择合适的硬件和服务。
- 使用模型压缩技术:通过修剪、量化和蒸馏等技术,可以减少部署所需的内存和计算资源。
- 利用云计算服务:AWS、Google Cloud和Microsoft Azure等云服务提供了经济高效且可扩展的解决方案。
- 采用无服务器计算:无服务器计算提供了按使用付费的模式,可以降低运营成本并实现自动扩展。
- 优化硬件加速:例如,我们可以使用GPU来加速模型的训练和推理,从而提高效率。
- 定期监控资源使用:通过监控,我们可以识别哪些资源被低效使用,或者哪些实例被过度配置,从而找到降低成本的机会。
- 持续优化模型和硬件:我们需要不断地优化我们的模型和硬件配置,以实现高效的推理。
- 更新软件和安全补丁:保持软件和安全补丁的最新状态,以确保我们的系统的安全。
在本文中,我们探讨了部署大型语言模型时面临的挑战,以及与之相关的基础设施成本。同时,我们也提出了解决这些问题的技术和策略。
在我们讨论的所有解决方案中,风爷最推荐的是弹性和无服务器推理。虽然模型压缩是一种有效的方法,但是当需求很高时,即使是较小的模型也可能需要大量的资源。因此,需要一个可以根据需求动态调整资源的解决方案,这就是弹性和无服务器推理的优势。
当然,这些推荐可能并不适合所有的情况,你需要根据你自己的需求和问题来选择最合适的方法。风爷希望这些讨论可以帮助你在部署大型语言模型时降低基础设施成本。
智写AI介绍
智写AI是免费万能的ai写作聊天机器人。ai免费帮你写作文、写论文、写材料、写文案、写网络小说、写周报月报、公务员材料、行政报告、写英语作文、写小说剧本、写短视频脚本、写营销文案等等,还能写代码。它能教你python、java、C#、C、javscript、Golang编程、系统架构设计、系统开发。它还能教你简历制作、简历模版,给你做心理咨询、给你讲故事、陪你玩文字游戏等。
#AIGC #LLMs #Infra #AWS #大模型
References 参考文献
- Large Language Model Training in 2023
- https://d1.awsstatic.com/events/Summits/reinvent2022/AIM405_Train-and-deploy-large-language-models-on-Amazon-SageMaker.pdf
- Top 10 AI Chip Makers of 2023: In-depth Guide
- https://www.nvidia.com/en-us/data-center/dgx-a100/
- LLaMA: A foundational, 65-billion-parameter large language model
- https://arxiv.org/pdf/2203.15556.pdf
- https://huggingface.co/docs/transformers/model_doc
- https://huggingface.co/docs/transformers/model_doc/gpt2#transformers.GPT2TokenizerFast
- https://sunniesuhyoung.github.io/files/LLM.pdf
- https://twitter.com/tomgoldsteincs/status/1600196995389366274?lang=en
- https://arxiv.org/pdf/1910.02054.pdf
- https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-model.html
- Jaime Sevilla et al. (2022), “Estimating Training Compute of Deep Learning Models”. Published online at epochai.org. Retrieved from: ‘https://epochai.org/blog/estimating-training-compute‘ [online resource]
- https://arxiv.org/abs/2001.08361
- https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet-us-nvidia-1758950-r4-web.pdf
- https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-model.html
- https://aws.amazon.com/sagemaker/neo/
- https://colab.research.google.com/github/pytorch/tutorials/blob/gh-pages/_downloads/7126bf7beed4c4c3a05bcc2dac8baa3c/pruning_tutorial.ipynb
- https://towardsdatascience.com/distillation-of-bert-like-models-the-code-73c31e8c2b0a
- https://aws.amazon.com/blogs/machine-learning/train-175-billion-parameter-nlp-models-with-model-parallel-additions-and-hugging-face-on-amazon-sagemaker/
- Improving Language Model Behavior by Training on a Curated Dataset
- https://towardsdatascience.com/how-to-deploy-large-size-deep-learning-models-into-production-66b851d17f33
- https://huggingface.co/blog/large-language-models
- https://aws.amazon.com/blogs/machine-learning/deploy-large-models-on-amazon-sagemaker-using-djlserving-and-deepspeed-model-parallel-inference/
- Large Language Models Can Self-Improve
- https://spot.io/resources/cloud-cost/cloud-cost-optimization-15-ways-to-optimize-your-cloud/
- https://dataintegration.info/choose-the-best-ai-accelerator-and-model-compilation-for-computer-vision-inference-with-amazon-sagemaker
- https://medium.com/data-science-at-microsoft/model-compression-and-optimization-why-think-bigger-when-you-can-think-smaller-216ec096f68b
- https://medium.com/picsellia/how-to-optimize-computer-vision-models-for-edge-devices-851b20f7cf03
- https://huggingface.co/docs/transformers/v4.17.0/en/parallelism#which-strategy-to-use-when
- https://medium.com/@mlblogging.k/9-libraries-for-parallel-distributed-training-inference-of-deep-learning-models-5faa86199c1f
- https://towardsdatascience.com/how-to-estimate-and-reduce-the-carbon-footprint-of-machine-learning-models-49f24510880