向量数据库入门教程系列-1-基于pinecone实现语义搜索
1. Pinecone简介
Pinecone是一个简单的云原生向量数据库,为高性能的AI应用提供长期记忆。它适用于涉及大模型(LLM)、生成式人工智能(AIGC)和语义搜索(Sematic Search)的应用。使用Pinecone,可以轻松存储和查询Vector ,提供优化的性能和实时分析能力。
1.1 与Mysql对比
| 特性/数据库 | Pinecone | MySQL |
|---|---|---|
| 数据类型 | 向量数据 | 结构化数据(如文本、数字、日期等) |
| 数据结构 | 无模式,数据以高维向量形式存储 | 表格结构,数据以行和列的形式组织 |
| 索引 | 为高维向量优化的索引 | B树、哈希索引等 |
| 存储方式 | 分布式存储,云原生 | 可以是本地存储或分布式存储(如MySQL Cluster) |
| 查询复杂性 | 主要用于相似性搜索 | 支持复杂的SQL查询,如连接、子查询等 |
| 数据模型 | 无模式 | 有模式,需要预先定义表、列和关系 |
1.2 Pinecone特点
速度快:Pinecone利用了突破性的新算法,可以实现毫秒级的向量搜索,是传统搜索方法的100-1000倍速度。这使得它非常适合需要实时响应的应用。
易于集成:Pinecone提供了多种语言的客户端库,包括Python、Java、Go等,可以非常容易地在应用中集成Pinecone。并且支持主流机器学习框架,如TensorFlow、PyTorch等。
灵活可扩展:Pinecone使用了可水平扩展的分布式架构,可以根据需求轻松扩展搜索能力。并且提供了细粒度的可调参数,可以针对不同的应用场景进行优化。
可管理的SaaS:Pinecone提供了云托管的SaaS版本,开发者可以通过简单的WEB界面来管理索引和查询,无需自行部署和维护服务。
2. 初识Pinecone
如前文所说,Pinecone是云原生的应用,它直接登陆网页就能使用。借助传统数据库的概念,我们来快速了解一下Pinecone的数据结构。
- Pod:它是一个运行Pinecone服务的预配置硬件单元,你可以理解成一个运行Docker上的数据库实例。
- Index:可以理解成传统关系数据库的表(Table)。每个Index在Pinecone中都是一个独立的数据结构,用于存储和检索高维向量。每个索引都有其自己的数据集和相关的配置。查询和操作是针对特定Index进行的。
- Record: 可以理解成传统关系数据库的行(Row)。每个记录都有一个唯一的ID或键。
接下来进入实战:
2.1 数据库创建
构建Pinecone数据库是极其简单的,只需要在网页上点击几下,填写一些必要的参数即可。
2.1.1 登陆注册
2.1.2 容器类型和索引(Pod Type& Index )
创建一个index,最核心的参数是维数,这个很多时候取决于你的数据大小。Pod Type如前文所言,服务实例的大小,我们免费用户只能选择starter这个机型。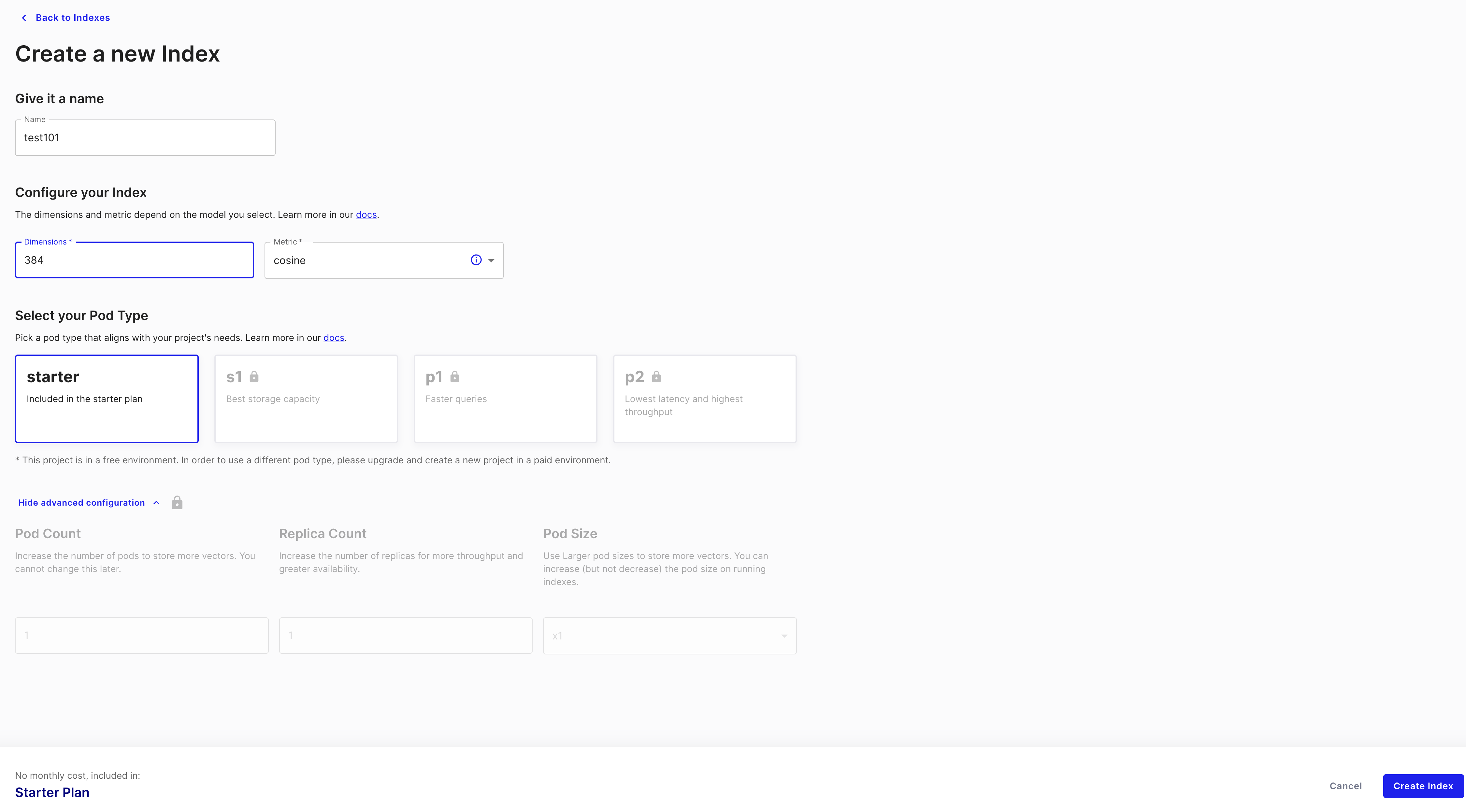
可以看到我们创建了一个名字为test101的index,维度为384维。注意一开始这个vectors应该是零。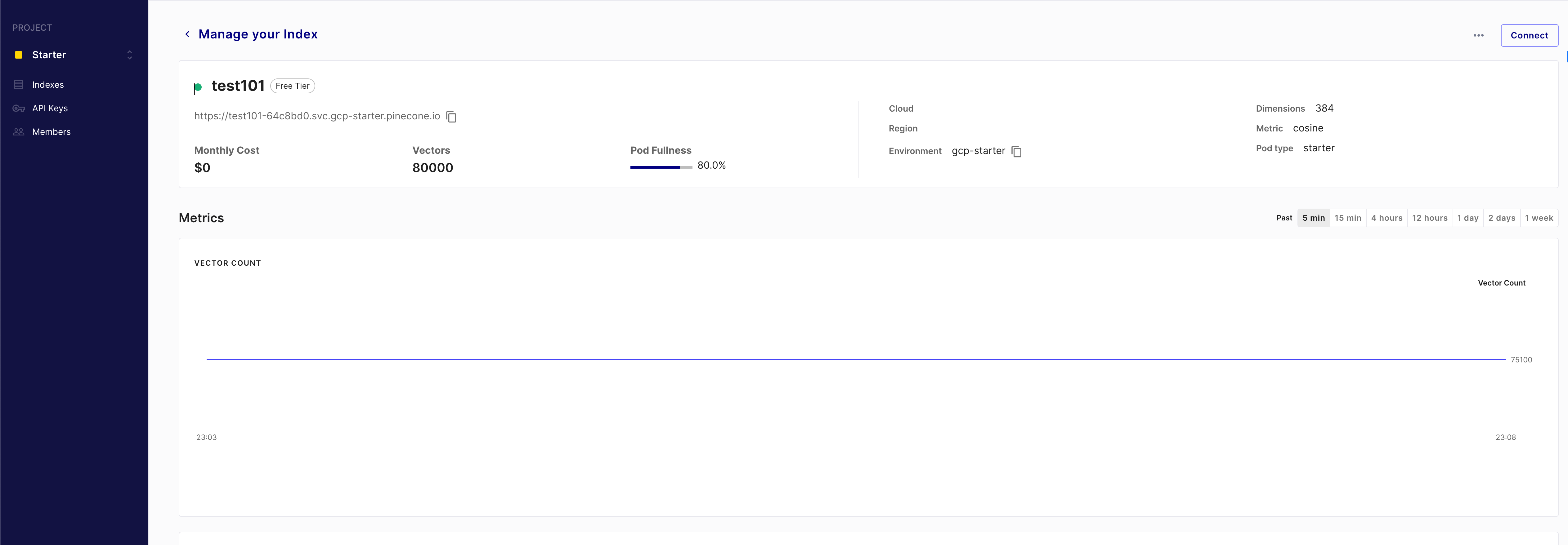
后续我们通过客户端向数据库上传了80000个vector到这个index。
2.1.3 记录(record)
Pinecone索引中的每个记录record包含一个唯一的ID和一个表示密集向量嵌入的浮点数数组,可以看到数据结构实际上这样。
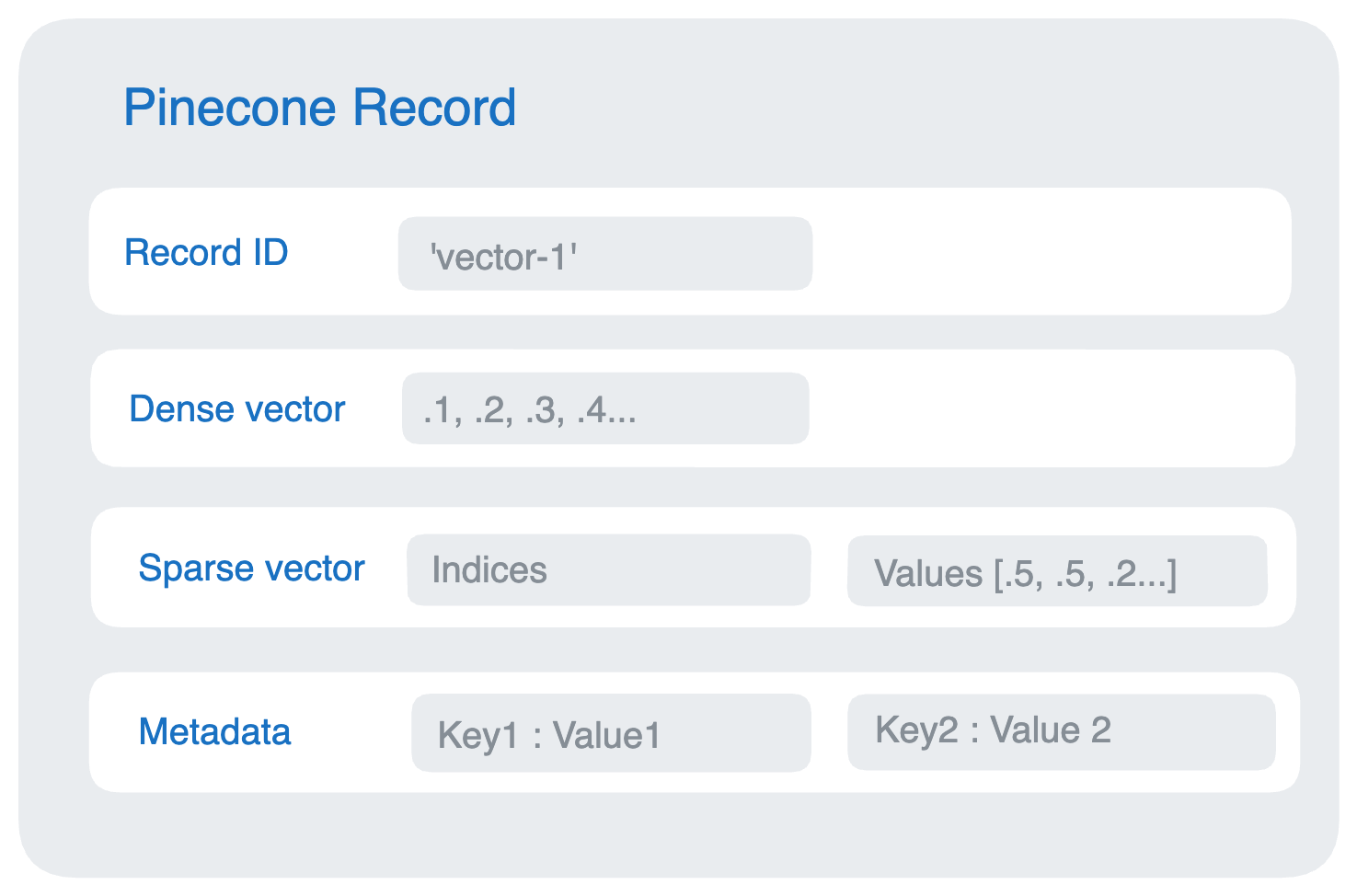
Pinecone基本上是以JSON格式来对数据库做CURD,我们来看看一个最简单Record例子: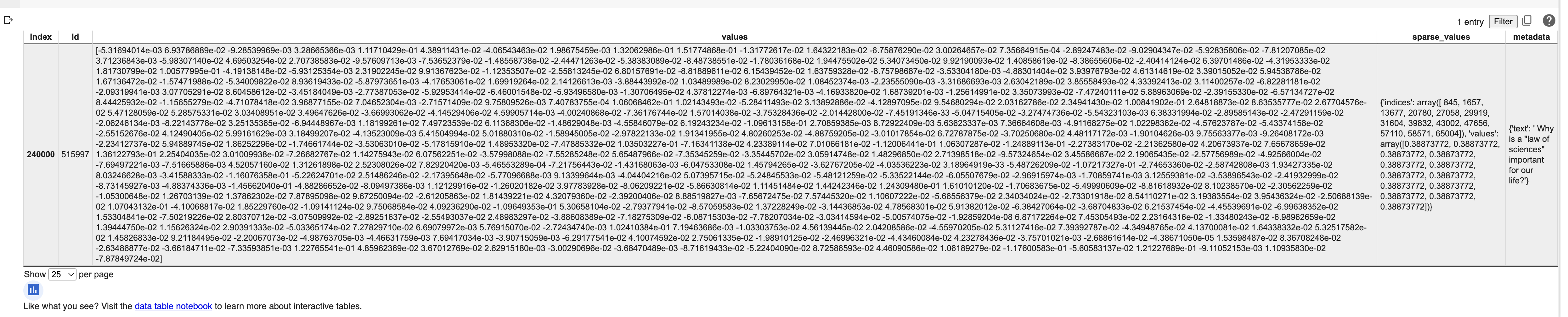
这个Record由4个字段组成,分别是RecordID,可以理解为RowId,唯一标识符。Dense Vector和Sparse Vector都是指我们数据的向量表达方式。MetaData就是元数据。
3 基于Pinecone实现语义搜索
- 安装依赖包
1 | !pip install -qU \ |
我们跳过数据准备步骤,因为它们非常耗时,直接使用Pinecone Datasets中的预建数据集来进行操作。这次教程中使用的是quora_all-MiniLM-L6-bm25,主要是美国知乎的提问问题。
- *下载数据集
Starter这个pod支持写入10万条vector,我们选择8万条数据写入。
1 | from pinecone_datasets import load_dataset |
可以看到前10条数据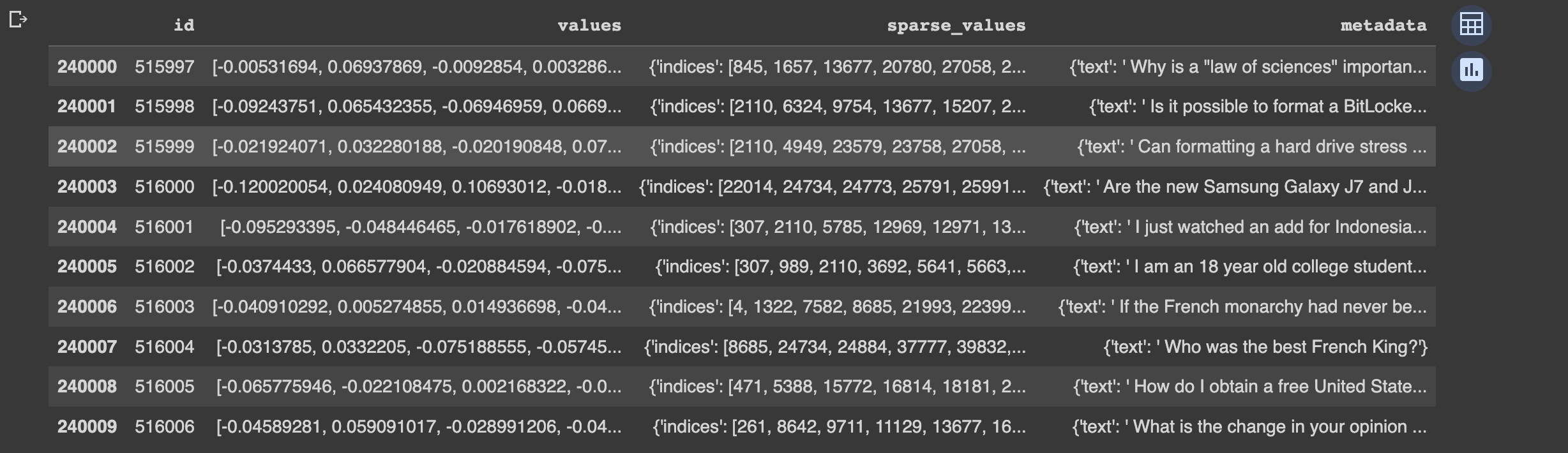
配置环境
1
2
3
4
5
6
7
8
9
10
11
12import os
import pinecone
# 找到你的PINECONE_API_KEY
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY') or 'PINECONE_API_KEY'
# 找到你的PINECONE_ENVIRONMENT
PINECONE_ENV = os.environ.get('PINECONE_ENVIRONMENT') or 'PINECONE_ENVIRONMENT'
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_ENV
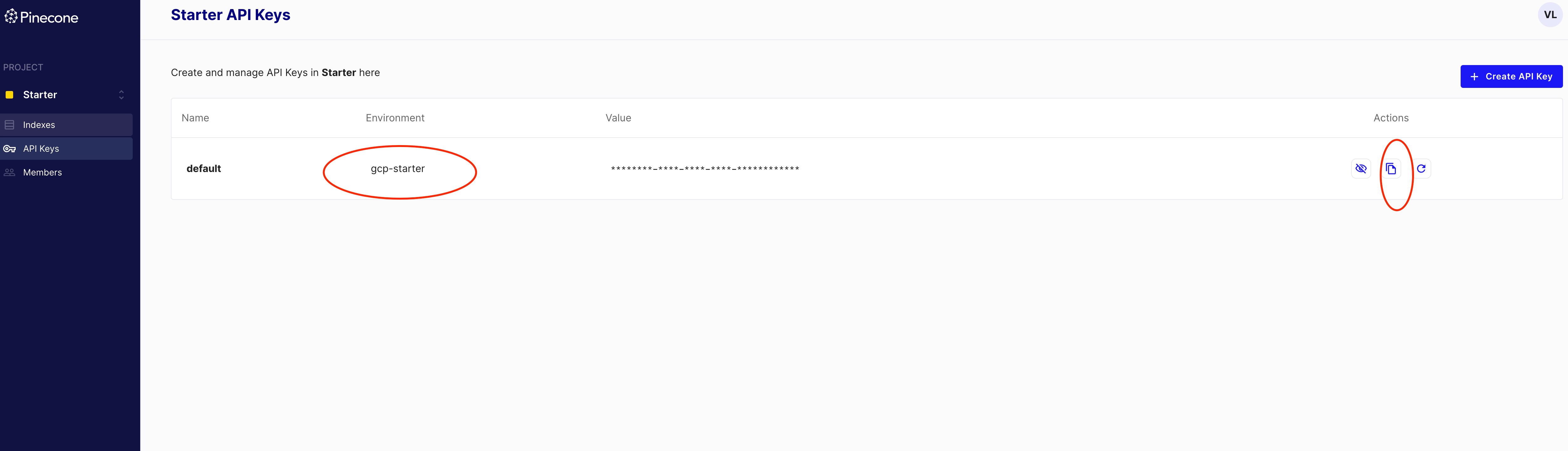
)如下图所示:第一个红色圆圈为PINECONE_ENVIRONMENT的参数取值。第二个圆圈为PINECONE_API_KEY的参数取值。复制粘贴到上述代码里面替换成字符串即可。
创建名为test101的index
1
index_name = 'test101'
1 |
|
批量写入数据:
1 | for batch in dataset.iter_documents(batch_size=100): |
可以看到写入的性能曲线,有个比较陡峭的峰,感觉性能并没有很稳定。另外,数据图表有个小bug,只显示有75000条,和上面的统计信息有所冲突。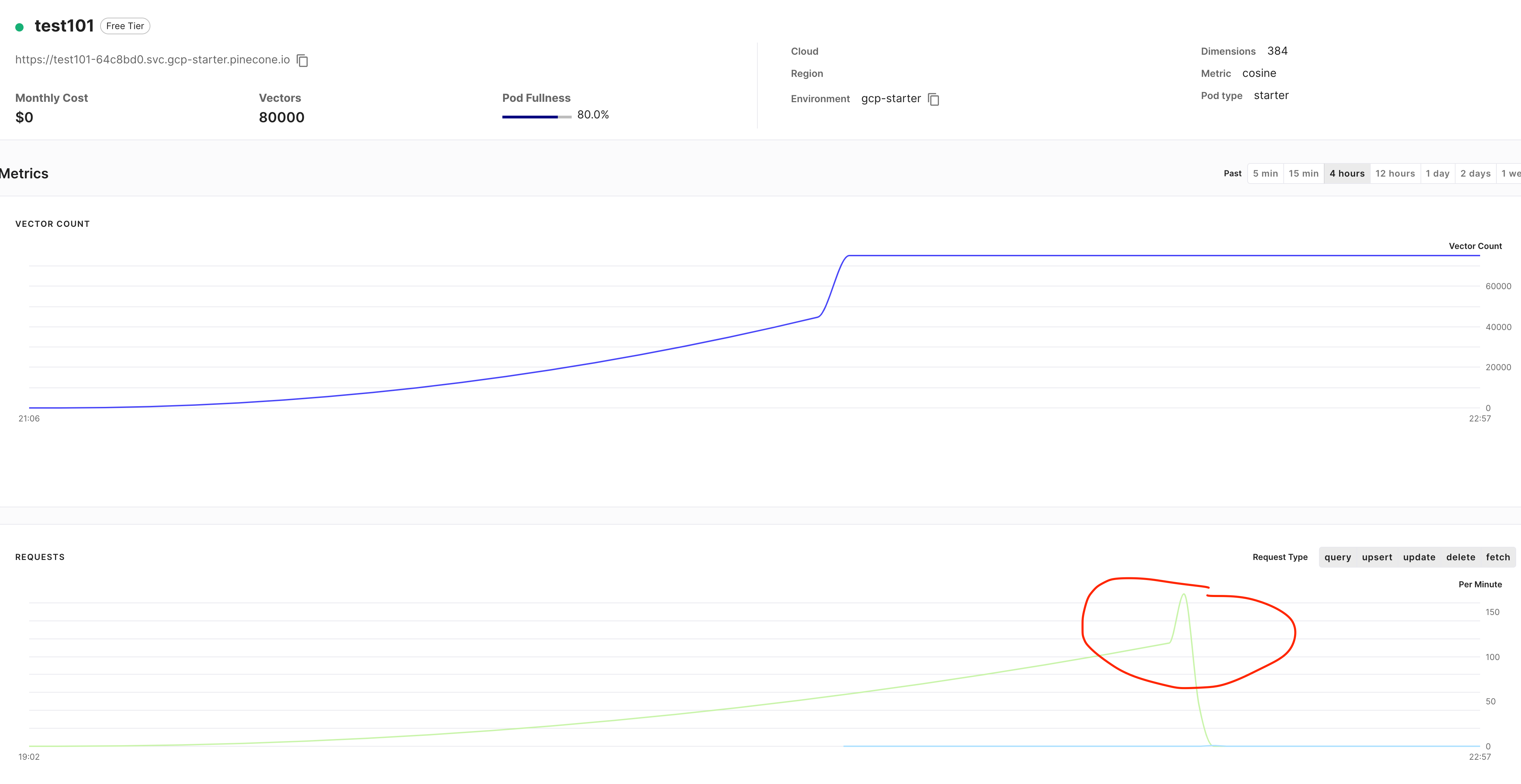
Index的数据已经写入,可以开始进行查询了。语义搜索需要将文本转换成向量的形式,也就是我们通常所说的vector embeddings过程。在本教程里,我们采用SentenceTransformer来实现句子vector embeddings(向量嵌入)。
SentenceTransformer是一个功能强大的,可以生成句子、文本和图像的embeddings的python库。它提供了许多已经训练好的模型,用户可以使用这些模型进行文本相关任务,例如文本相似度计算、文本分类等。
1 | from sentence_transformers import SentenceTransformer |
可以看到模型的一些默认信息:
- 查询你的问题向量
1
2
3
4
5
6
7
8
9
10
11query = "Who was the best Chinese King?"
# 创建一个查询的向量
xq = model.encode(query).tolist()
# 查询
xc = index.query(xq, top_k=5, include_metadata=True)
# 逐一打印结果
for result in xc['matches']:
print(f"{round(result['score'], 2)}: {result['metadata']['text']}")
结果如下图所示:数字表示相似度,展现了相似度排名前五的问题向量。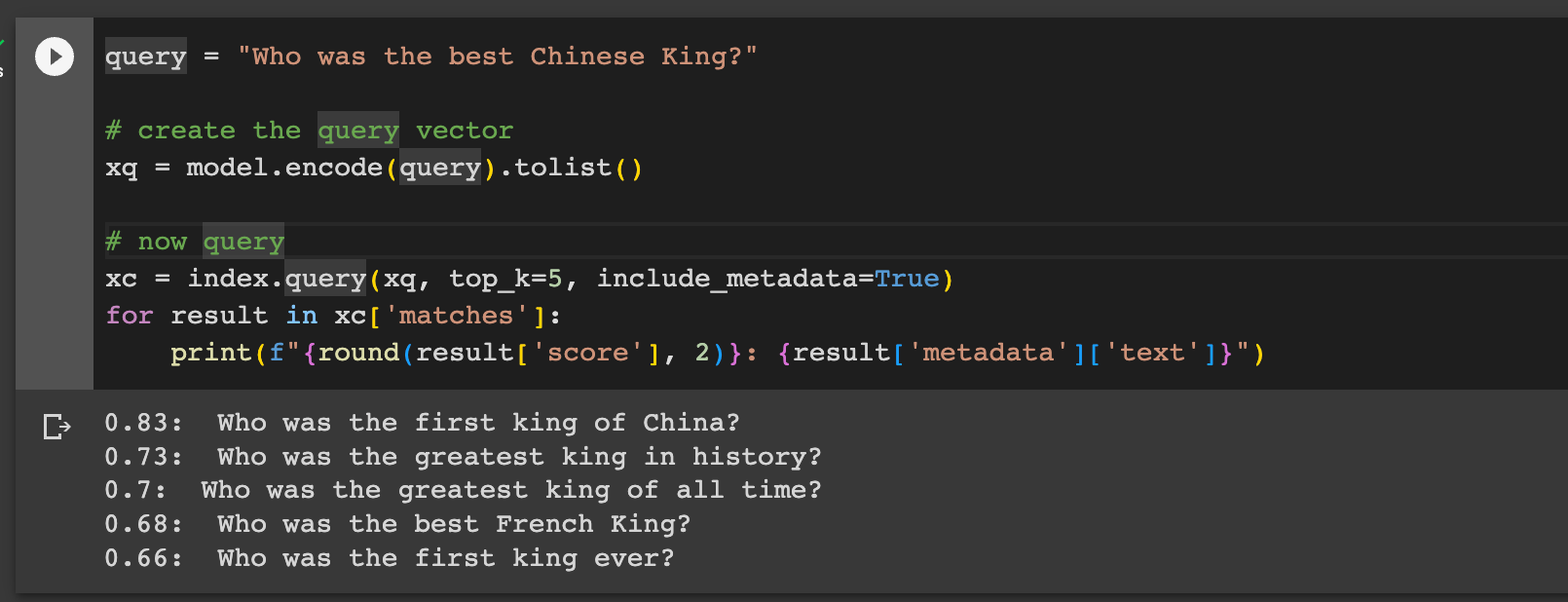
4. 总结
本文深入探讨了Pinecone,一款云原生向量数据库,强调了其与传统数据库如MySQL的差异。Pinecone的核心优势在于其高速、易集成、灵活性和云托管能力。通过实际示例,我们展示了如何使用Pinecone和SentenceTransformer进行语义搜索。在接下来的教程中,风爷将进一步探索如何结合向量数据库和大型模型来实现图片的语义搜索,为大家展示向量数据库更多的实际应用场景。
智写AI介绍
智写AI是免费万能的ai写作聊天机器人。ai免费帮你写作文、写论文、写材料、写文案、写网络小说、写周报月报、公务员材料、行政报告、写英语作文、写小说剧本、写短视频脚本、写营销文案等等,还能写代码。它能教你python、java、C#、C、javscript、Golang编程、系统架构设计、系统开发。它还能教你简历制作、简历模版,给你做心理咨询、给你讲故事、陪你玩文字游戏等。
向量数据库入门教程系列-1-基于pinecone实现语义搜索
https://www.alidraft.com/2024/02/12/vector-database-step-by-step-tutorial-1/