GPT成功背后的秘密--向量数据库简介
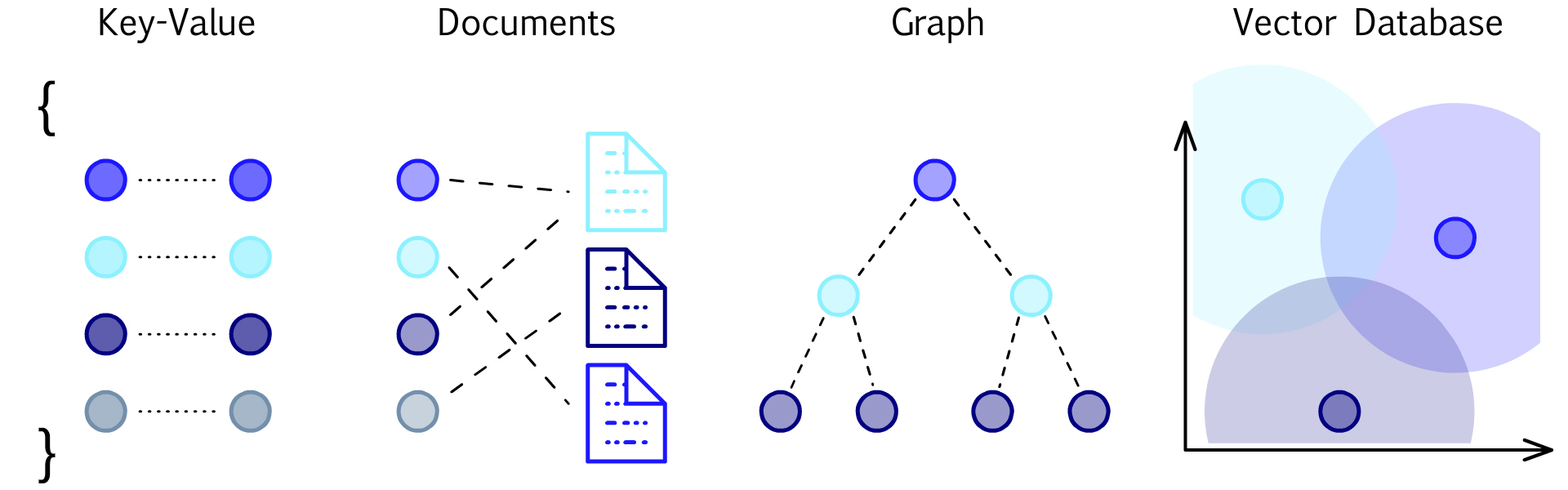
介绍
互联网上复杂的非结构化数据正在以惊人的速度增长,比如文档、图像、视频和普通文本等形式。许多公司、组织将受益于存储和分析复杂数据,但传统数据库针对结构化数据建立,处理非结构化数据可能会很困难。如果仅通过关键词分析、数据分类可能不足以完全表示挖掘和学习到这些数据所蕴含的知识。
幸运的是,机器学习里面有一种技术叫做:向量嵌入(vector embeddings)。向量嵌入将复杂数据对象转换为在数百或数千个不同维度的数值。(简单理解为大矩阵)。目前有许多技术用于构建向量嵌入,存在一些现有的公共模型,它们具有高性能并且易于使用。
向量数据库需要专门设计处理向量嵌入的独特结构,通过比较值并找到彼此最相似的向量来索引向量,以便进行易于搜索和检索。实现的技术难度比较高,到目前为止,矢量数据库只有少数拥有大量开发和管理资源的技术巨头才能使用。
什么是向量嵌入(vector embeedings)
向量嵌入(vector embedding)是一种将非数值的词语或符号编码成数值向量的技术。它是自然语言处理(NLP)和深度学习中常用的预处理技术。
通常,向量嵌入是通过一个神经网络来学习的,该网络接收文本中的词语作为输入,并输出一个对应的词向量,其中词向量是一个数值向量,每个数值代表词语的某个特征。
例如,通过向量嵌入,我们可以将词语”dog”和”cat”表示为两个不同的数值向量,并可以通过计算两个向量的距离来判断它们的相似度。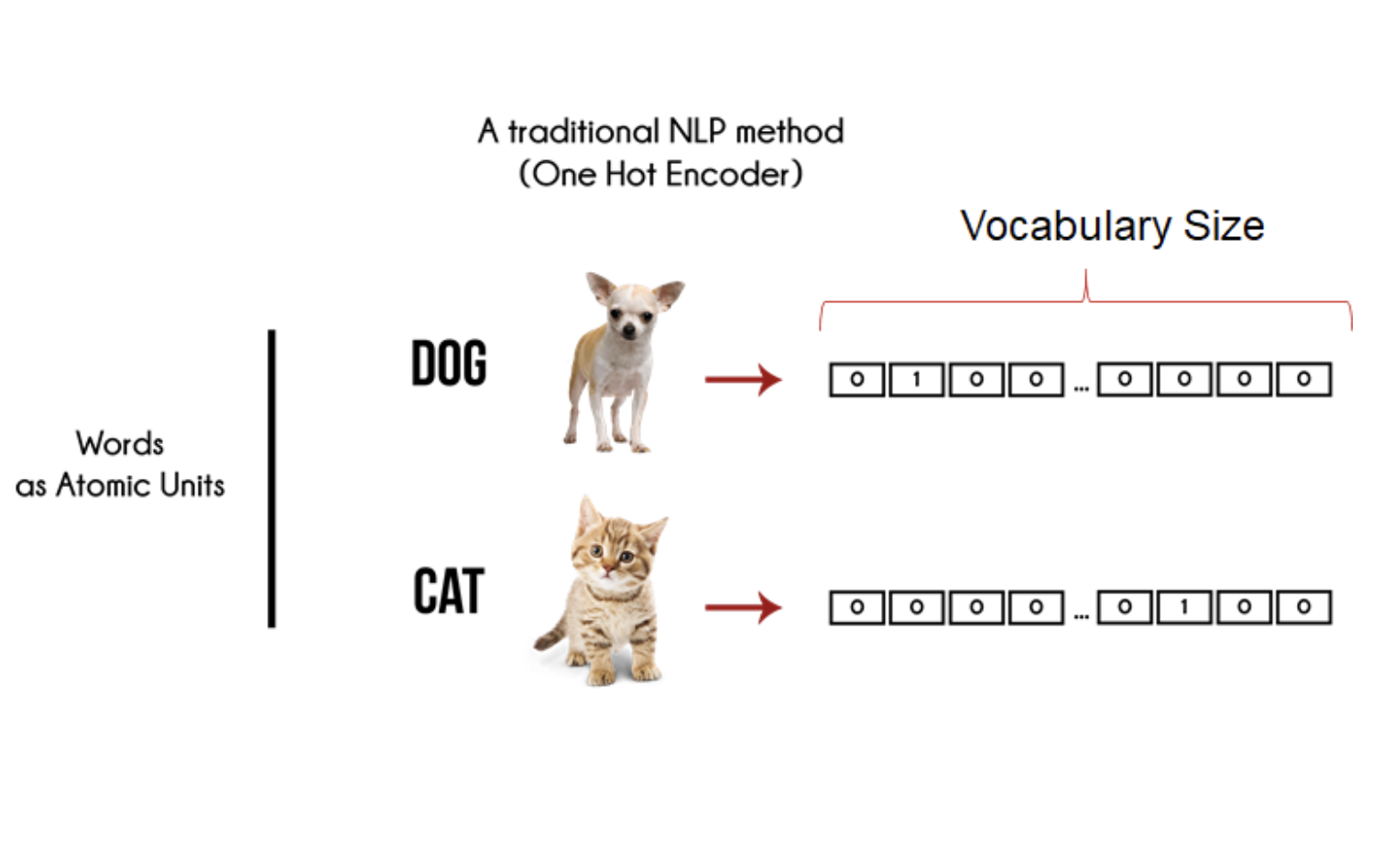
如果发现通过向量映射还不好理解的话,把词向量在高维空间的嵌入投影,可视化出来就能很轻松得搞明白。词义相近的词组,会在高维空间上”距离“更近。(非常重要的理论基础)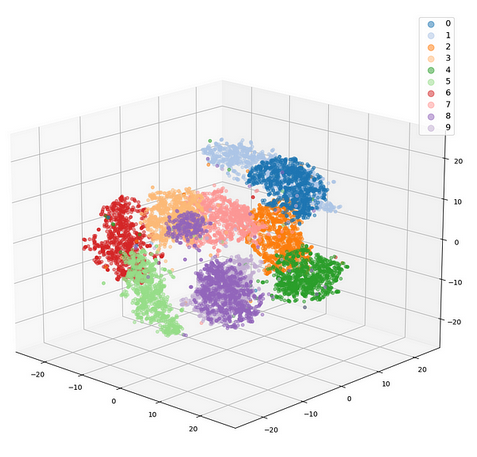
什么是向量数据库
向量数据库是一种将数据存储为高维向量的数据库,高维向量是特征或属性的数学表示。每个向量都有一定数量的维度,范围从几十到几千不等,具体取决于数据的复杂性和粒度。向量数据库同时具有CRUD操作、元数据过滤和水平扩展等功能。
向量通常是通过对原始数据(例如文本、图像、音频、视频等)应用某种变换或嵌入函数来生成的。嵌入函数可以基于各种方法,例如机器学习模型、词嵌入、特征提取算法。
向量数据库的主要优点是它允许根据向量距离或相似性对数据进行快速准确的相似性搜索和检索。这意味着您可以使用向量数据库根据语义或上下文含义查找最相似或相关的数据,而不是使用基于精确匹配或预定义标准查询数据库的传统方法。
它们将向量嵌入组织在一起,使我们能够比较任何向量与搜索查询的向量或其他向量之间的相似度。它们也可以执行CRUD操作和元数据过滤。将传统数据库功能与搜索和比较向量的能力相结合,使得向量数据库成为强大的工具。它们在相似度搜索方面表现出色,或称为“向量搜索”。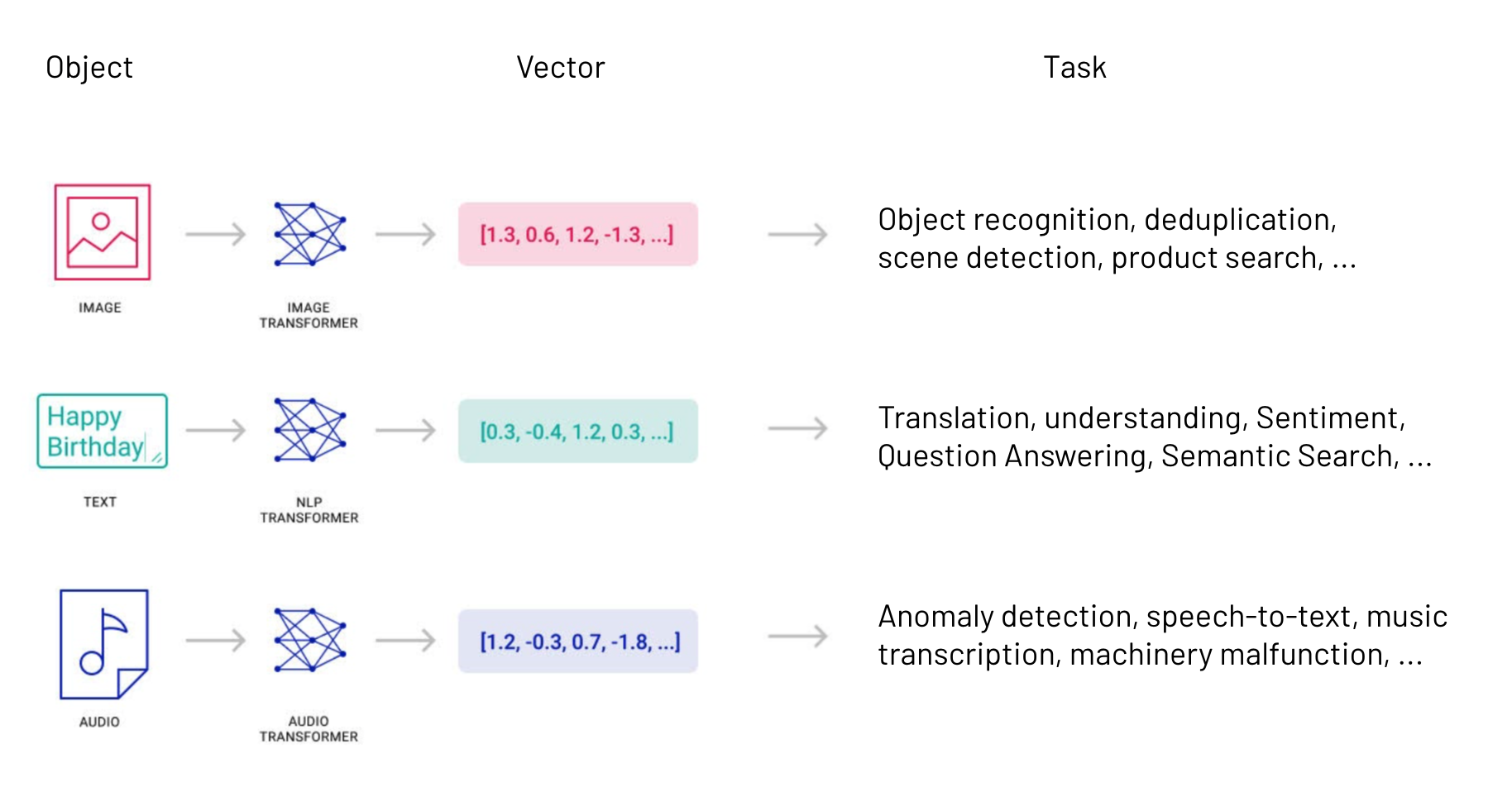
通过向量搜索,用户可以描述他们想要找到什么,而不必知道存储对象所归属的关键字或元数据分类。同时,向量搜索还可以返回类似或近邻匹配的结果,提供了更全面的结果列表,否则这些结果可能会被隐藏起来。
向量数据库能干什么?
让我们来看一些向量搜索的常见用例:
1. 语义搜索
文本搜索通常有两种方式:词法搜索和语义搜索。词法搜索是基于模式寻找精确单词或字符串匹配,就是平时我们常说的关键字匹配。语义搜索则将搜索查询或问题的含义放入上下文中,以理解文本的含义和上下文,并获得更准确和相关的搜索结果。
向量数据库,存储和索引自然语言处理模型中的向量嵌入,以更好地理解文本字符串、句子和整个文档。使用语义搜索可以让用户更快地找到所需内容,无需了解数据分类。这不仅提供了更好的用户体验,还能提高效率。
2. 对图像、音频、视频等非结构化数据进行相似度搜索
传统数据库难以分类和存储非结构化数据集,如图像、音频、视频等。对每个对象手动应用关键字、描述和元数据也很繁琐。不同人对复杂数据对象的分类可能有所不同,使得搜索变得随意。向量数据库能够更好理解数据,对数据进行相似度搜索。
3.搜索、推荐排序
做过搜索或者推荐排序的同学,应该对FAISS 这个库都不陌生,它是一个出色向量相似搜索类库。
向量数据库是一个类似的优秀的解决方案,可用于驱动排名和推荐引擎。向量数据库具备寻找相似物品的能力,因此它成为提供相关建议和轻松排名物品的理想选择。相似度分数也可用于对物品进行排序。
因此电商领域,可以用它为用户提供与过去购买或当前正在研究的物品相似的建议。流媒体服务(音乐、短视频)可以根据用户的歌曲评级创建个性化推荐。
4. 异常检测
既然向量数据库能够很好帮人们找到相似对象,做过异常检测(风控)的小伙伴们肯定也了解,其实聚类算法做得好,那么离群检测肯定也能做好。因为原理是一体两面的,能很快很好的找到相似的实体对象,那么找到不同的对象也是轻而易举。向量数据库在这些方向的应用是非常有效的。
向量数据库实例
推荐一些向量数据库,其中包括Pinecone ,ChatGPT,AutoGPT都基于它。还有一些开源方案可以关注。
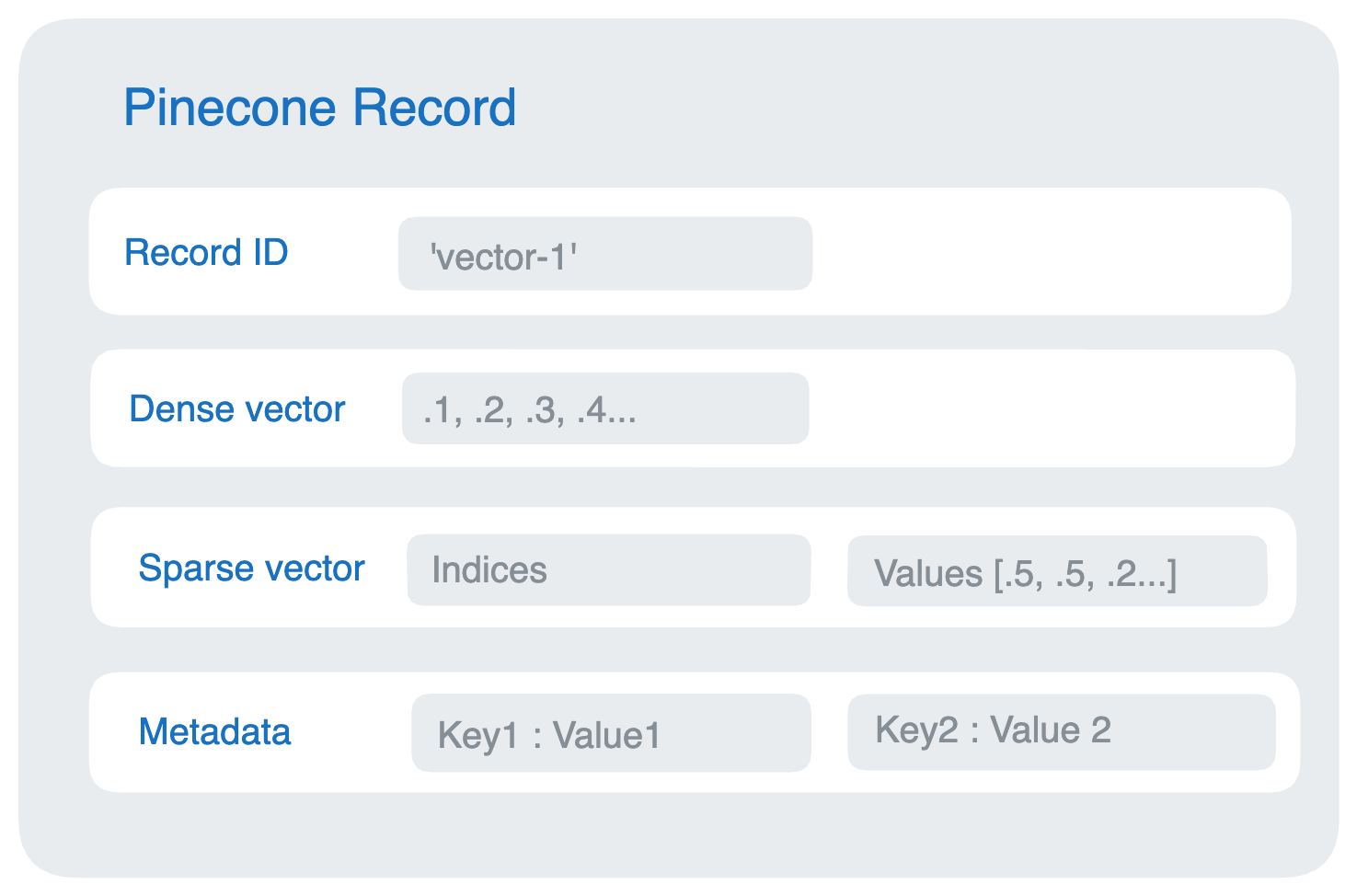
- Pinecone:Pinecone 是一个向量数据库,用于索引和存储向量嵌入以进行快速检索和相似性搜索。它具有 CRUD 操作、元数据过滤和横向扩展等功能。
- Weaviate:Weaviate 是一个开源的向量数据库,允许您在原始向量或数据对象上执行闪电般快速的纯向量相似性搜索,甚至带有过滤器。它还允许您将基于关键字的搜索与向量搜索技术相结合,以获得最先进的结果。

- Chroma:Chroma 是一个向量数据库,为存储和搜索高维向量提供简单的 API。它专为基于特征和属性检索数据的相似性搜索而设计。
- Kinetica:Kinetica 是一个 GPU 加速的数据库,可以存储和查询高维向量。它使用内存计算和分布式处理的组合来提供快速的查询性能。
为什么需要向量数据库:
答案很简单:性能。
向量数据库针对大量向量数据的存储和执行操作进行了优化,每次查询通常处理数亿个向量,并且比传统数据库的处理速度快得多。以下主要介绍向量数据库最核心的几种技术和能力:
- 执行复杂的数学运算,使用“余弦相似度”等聚类技术过滤和定位“附近”的向量
- 提供专门的 Vector 索引,使数据检索速度显着加快并更精确
- 以更紧凑的方式存储向量,例如通过压缩和量化向量数据,尽可能多地在内存中查询数据
- 跨多台机器数据分片
接下来我们深入了解一下相似性搜索相关技术:
相似性搜索向量索引
衡量向量之间的相关性和相似性,最常用的指标包括欧几里得距离、余弦相似度或点积。传统数据库的最近邻搜索需要比较每个已索引向量,效率比较低。
向量数据库使用“最近邻”索引来评估相似对象之间或搜索查询之间的接近程度。传统的最近邻搜索需要比较每个已索引向量,效率比较低。
向量数据库使用 近似最近邻(ANN)搜索技术,来评估相似对象之间或搜索查询之间的接近程度。
常用的技术包括HNSW、inverted file index(IVF)和 Product Quantization(PQ)等算法。
HHSW:
IVF: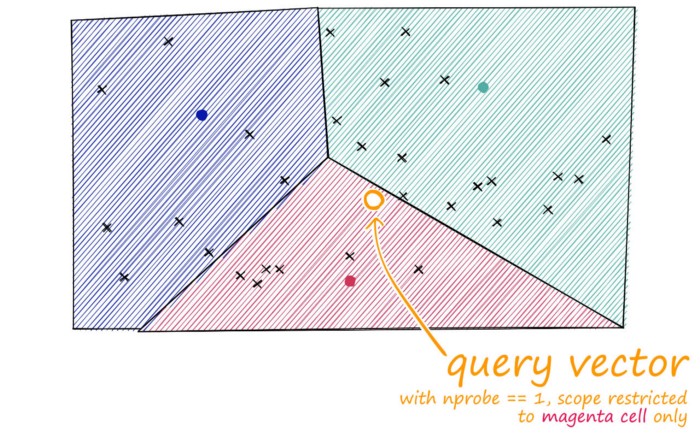
PQ:
总结
向量数据库是AI时代的核心组件,也是方兴未艾的领域,值得深入研究和发展。ChatGPT、AutoGPT类AI助手的崛起将会带来类似于MongoDB、Redis级别的数据库创业机会。
智写AI介绍
智写AI是免费万能的ai写作聊天机器人。ai免费帮你写作文、写论文、写材料、写文案、周报月报、公务员材料、行政报告、写英语作文、写小说剧本、写短视频脚本、写营销文案等等,还能写代码。它能教你python、java、C#、C、javscript、Golang编程、系统架构设计、系统开发。它还能教你简历制作、简历模版,给你做心理咨询、给你讲故事、陪你玩文字游戏等。
GPT成功背后的秘密--向量数据库简介
https://www.alidraft.com/2024/02/12/secret-for-gpt-vector-database/