AI技术行业动态头条-- 英伟达发布GH200超级芯片-- Aug-Week2-2023
1.大模型产业动态
1.1 英伟达在SIGGRAPH发布一系列产品更新
1.1.1 英伟达最强AI超算再升级——下一代GH200超级芯片平台
NVIDIA GH200 Grace Hopper将配备更加先进的HBM3e内存,要比当前的HBM3快了50%,10TB/s的带宽,也使得新平台可以运行比上一版本大3.5倍的模型,同时通过3倍更快的内存带宽提高性能。下一代GH200超级芯片平台由72核Grace CPU和4PFLOPS Hopper GPU组成,内存容量高达141GB,提供每秒10TB的带宽。其每个GPU的容量达到NVIDIA H100 GPU的1.7倍,带宽达到H100的1.55倍。将具有连接多个GPU的能力,从而实现卓越的性能和易于扩展的服务器设计。
这个拥有多种配置的全新平台,将能够处理世界上最复杂的生成式工作负载,包括大语言模型、推荐系统和向量数据库等等。

1.1.2 RTX工作站一口气推出了3款新品:RTX 5000、RTX 4500和RTX 4000
针对企业客户,皮衣老黄还准备一套一站式解决方案—— RTX Workstation。
支持最多4张RTX 6000 GPU,可以在15小时内完成8.6亿token的GPT3-40B的微调。
还能让Stable Diffusion XL每分钟生成40张图片,比4090快5倍。
1.1.3 AI Workbench:加速定制生成式AI应用
发布了全新的NVIDIA AI Workbench,来帮助开发和部署生成式AI模型。
AI Workbench为开发者提供了一个统一且易于使用的工具包,能够快速在PC或工作站上创建、测试和微调模型,并无缝扩展到几乎任何数据中心、公有云或NVIDIA DGX Cloud上。
1.2 AI Agent大进展:斯坦福 Smallville 虚拟小镇正式开源
斯坦福关于AI Agent的著名论文《Generative Agents: Interactive Simulacra of Human Behavior
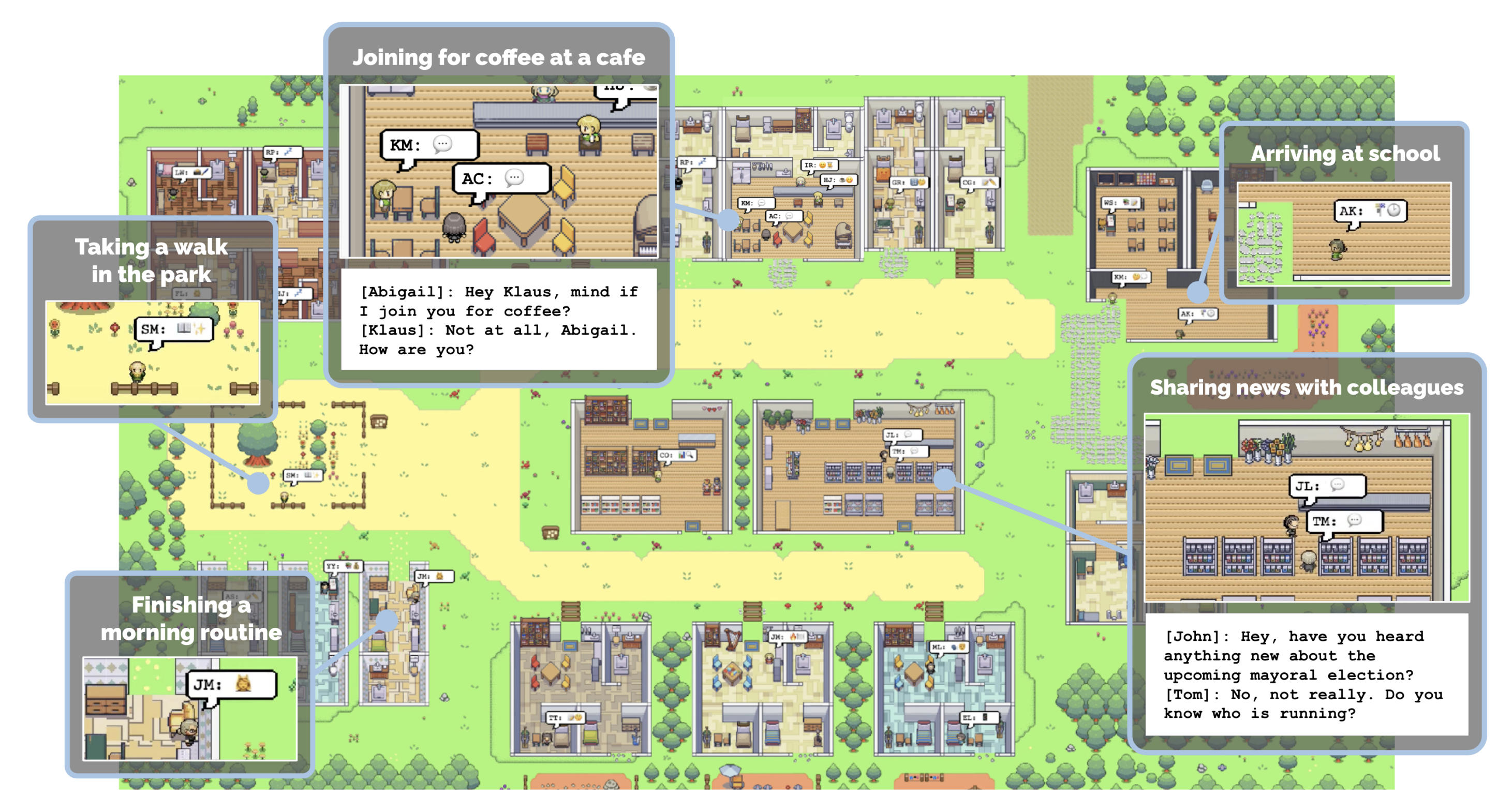
》的代码正式开源。Smallville 虚拟小镇正式开源,研究者们成功地构建了一个名为 Smallville 的虚拟小镇,25 个 AI 智能体在小镇上生活,他们有工作,会八卦,能组织社交,结交新朋友,甚至举办情人节派对,每个「小镇居民」都有独特的个性和背景故事。
这个开源项目它包含了我们用于生成代理的核心模拟模块——模拟可信人类行为的计算代理——以及它们的游戏环境。以下是在本地机器上设置模拟环境并回放模拟作为演示动画的步骤。
2.大模型学术动态
2.1 ACM SIGKDD 2023
KDD 2023 大会在美国加州长滩举办,是数据挖掘领域历史最悠久、规模最大的国际顶级学术会议。
来自香港中文大学的研究者获得了研究方向最佳论文奖,研究了在图领域中关于 prompting 的主题,旨在弥合预训练模型与各种图任务之间的差距,提出了一种新颖的用于图模型的多任务 prompting 方法;
来自谷歌的研究者获得了应用数据科学方向最佳论文奖,指出了导致模型训练不稳定的一些特性,并对其原因进行了推测。更进一步的,基于对训练不稳定点附近训练动态的观察,研究者假设了现有解决方案失败的原因,并提出了一种新的算法来减轻现有解决方案的局限性;
2.2 其他研究
2.2.1 Soft Moe
研究:关于低成本下的模型扩展针对计算成本较小且需要扩展模型大小的情况,Google DeepMind 的研究团队提出了“Soft MoE”新方法,解决稀疏混合专家架构(MoEs)训练不稳定、标记丢失、无法扩展专家数量或微调效果不佳的问题:模型大小在一定程度上被认为是影响模型性能的关键因素之一。通常,对于 Transformer 模型,模型越大,性能越好,同时计算成本增加。近期有研究表明,模型大小和训练数据必须一起扩展,才能最佳发挥效果。稀疏混合专家架构(MoEs)作为一种替代方案可以在不增加大量训练或推理成本的情况下扩展模型容量,但存在训练不稳定、标记丢失、无法扩展专家数量或微调效果不佳等问题。Google DeepMind 的研究团队提出Soft MoE,是完全可微分的稀疏Transformer,解决以上问题。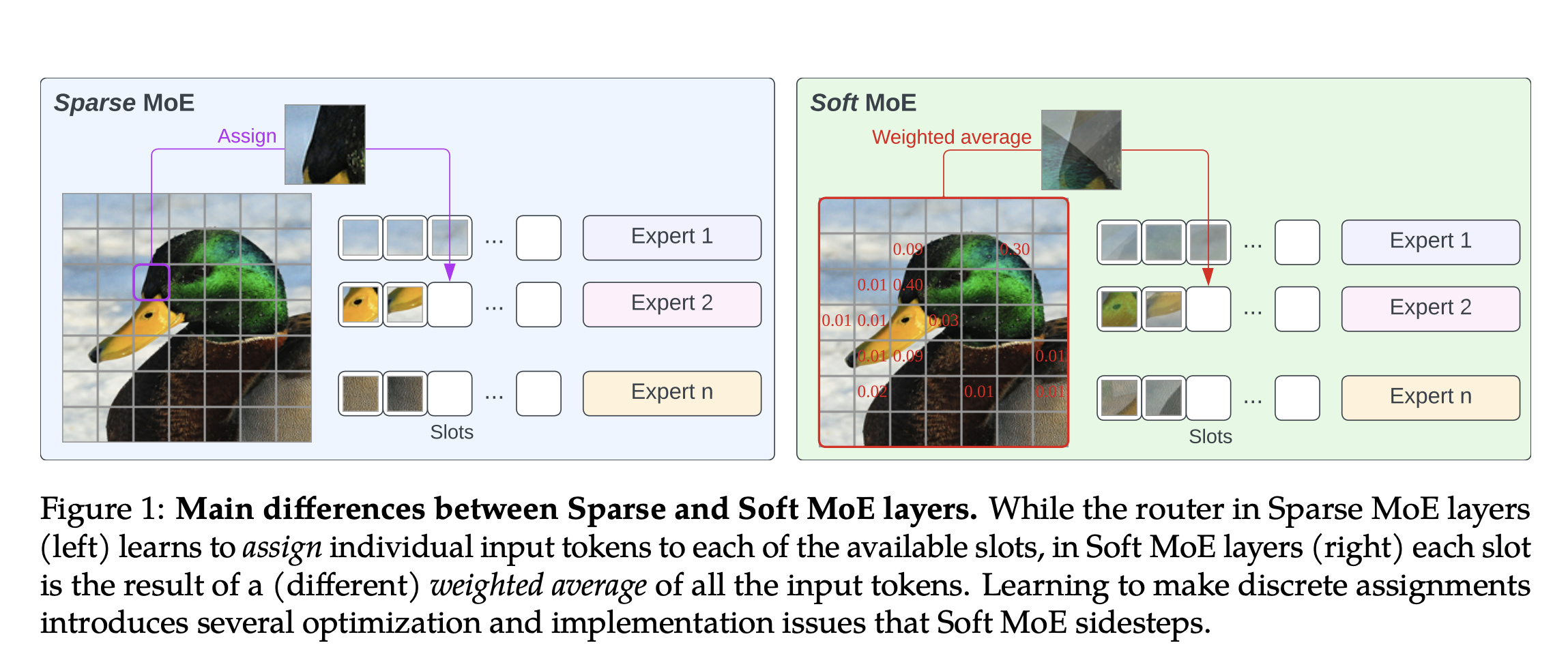
原文摘要:
Sparse mixture of expert architectures (MoEs) scale model capacity without large increases in trainingor inference costs. Despite their success, MoEs suffer from a number of issues: training instability, tokendropping, inability to scale the number of experts, or ineffective finetuning. In this work, we proposeSoft MoE, a fully-differentiable sparse Transformer that addresses these challenges, while maintaining thebenefits of MoEs. Soft MoE performs an implicit soft assignment by passing different weighted combinationsof all input tokens to each expert. As in other MoE works, experts in Soft MoE only process a subset ofthe (combined) tokens, enabling larger model capacity at lower inference cost. In the context of visualrecognition, Soft MoE greatly outperforms standard Transformers (ViTs) and popular MoE variants (TokensChoice and Experts Choice). For example, Soft MoE-Base/16 requires 10.5× lower inference cost (5.7×lower wall-clock time) than ViT-Huge/14 while matching its performance after similar training. Soft MoEalso scales well: Soft MoE Huge/14 with 128 experts in 16 MoE layers has over 40× more parameters thanViT Huge/14, while inference time cost grows by only 2%, and it performs substantially better.
2.2.2 AI Agent语言交互拓展
UC伯克利的研究人员提出从在线经验中学习语言和图像的多模态世界模型Dynalang,以及利用该模型学习如何行动的智能体:为了与人类互动并在世界中行动,智能体需要理解人们使用的语言范围,并将其与视觉世界联系起来。与仅使用语言预测行动的传统智能体不同,Dynalang通过使用过去的语言来预测未来的语言、视频和奖励,从而获得了丰富的语言理解。除了在环境中进行在线交互学习外,Dynalang还可以在没有行动或奖励的情况下预先训练文本、视频或两者的数据集。
原文摘要:
To interact with humans and act in the world, agents need to understand the range of language that people use and relate it to the visual world. While current agents learn to execute simple language instructions from task rewards, we aim to build agents that leverage diverse language that conveys general knowledge, describes the state of the world, provides interactive feedback, and more. Our key idea is that language helps agents predict the future: what will be observed, how the world will behave, and which situations will be rewarded. This perspective unifies language understanding with future prediction as a powerful self-supervised learning objective. We present Dynalang, an agent that learns a multimodal world model to predict future text and image representations and learns to act from imagined model rollouts. Unlike traditional agents that use language only to predict actions, Dynalang acquires rich language understanding by using past language also to predict future language, video, and rewards. In addition to learning from online interaction in an environment, Dynalang can be pretrained on datasets of text, video, or both without actions or rewards. From using language hints in grid worlds to navigating photorealistic scans of homes, Dynalang utilizes diverse types of language to improve task performance, including environment descriptions, game rules, and instructions.
2.2.3 清华与微软提出了一种全新「思维骨架」(SoT),大大减少了LLM回答的延迟
清华与微软合作提出了一种全新“思维骨架”(SoT),大大减少了LLM回答的延迟,并提升了回答的质量:由于当前先进的LLM采用了顺序解码方式,即一次生成一个词语或短语。然而,这种顺序解码可能花费较长生成时间,特别是在处理复杂任务时,会增加系统的延迟。受人类思考和写作过程的启发,来自清华微软的研究人员提出了「思维骨架」(SoT),以减少大模型的端到端的生成延迟。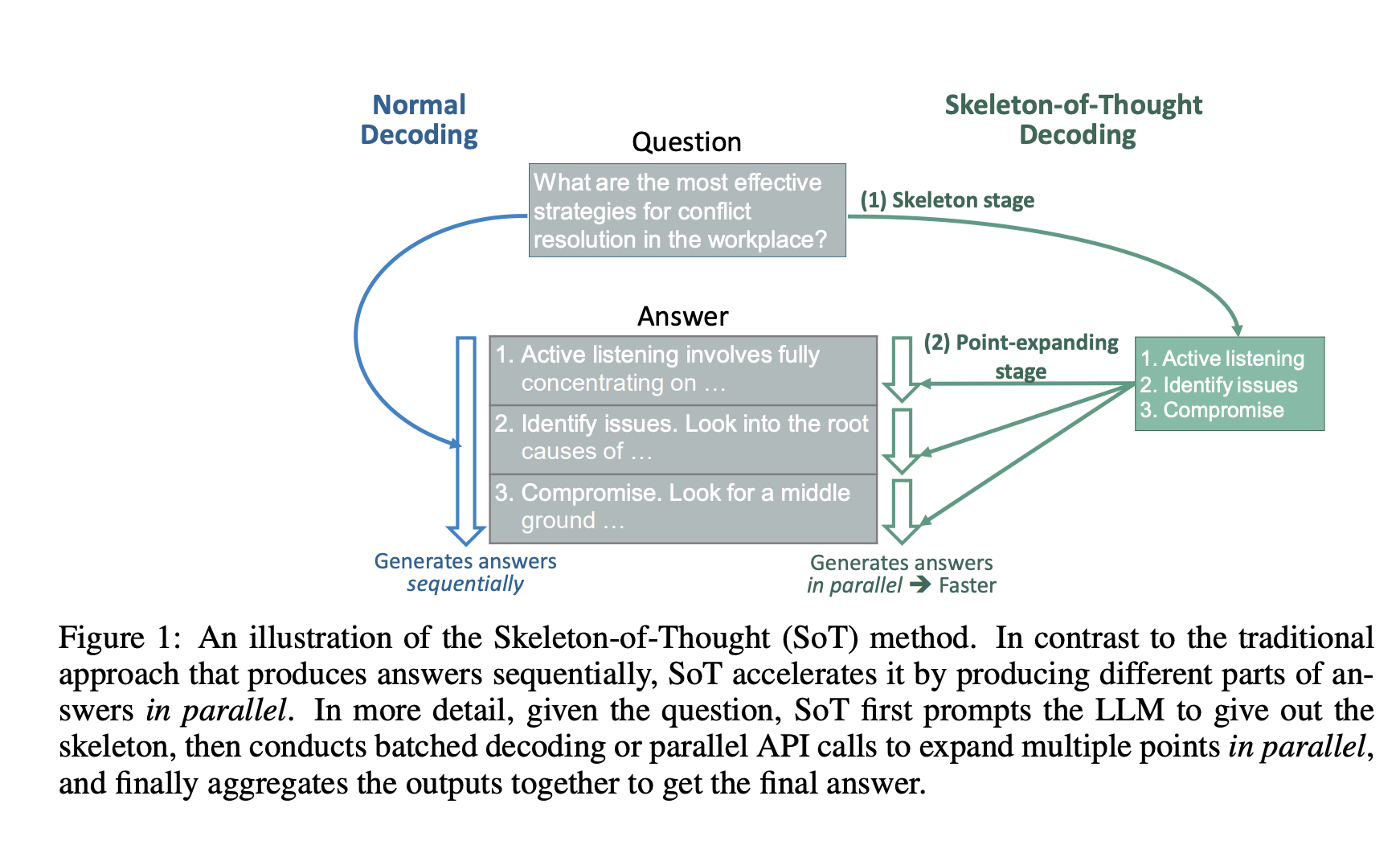
原文摘要:
This work aims at decreasing the end-to-end generation latency of large language models (LLMs). One of the major causes of the high generation latency is the sequential decoding approach adopted by almost all state-of-the-art LLMs. In this work, motivated by the thinking and writing process of humans, we propose “Skeleton-of-Thought” (SoT), which guides LLMs to first generate the skeleton of the answer, and then conducts parallel API calls or batched decoding to complete the contents of each skeleton point in parallel. Not only does SoT provide considerable speed-up (up to 2.39× across 11 different LLMs), but it can also potentially improve the answer quality on several question categories in terms of diversity and relevance. SoT is an initial attempt at data-centric optimization for efficiency, and reveal the potential of pushing LLMs to think more like a human for answer quality
智写AI介绍
智写AI是免费万能的ai写作聊天机器人。ai免费帮你写作文、写论文、写材料、写文案、写网络小说、写周报月报、公务员材料、行政报告、写英语作文、写小说剧本、写短视频脚本、写营销文案等等,还能写代码。它能教你python、java、C#、C、javscript、Golang编程、系统架构设计、系统开发。它还能教你简历制作、简历模版,给你做心理咨询、给你讲故事、陪你玩文字游戏等。
AI技术行业动态头条-- 英伟达发布GH200超级芯片-- Aug-Week2-2023
https://www.alidraft.com/2024/02/12/ai-news-headline-2023-Aug-W2/