一、大模型
- 模型
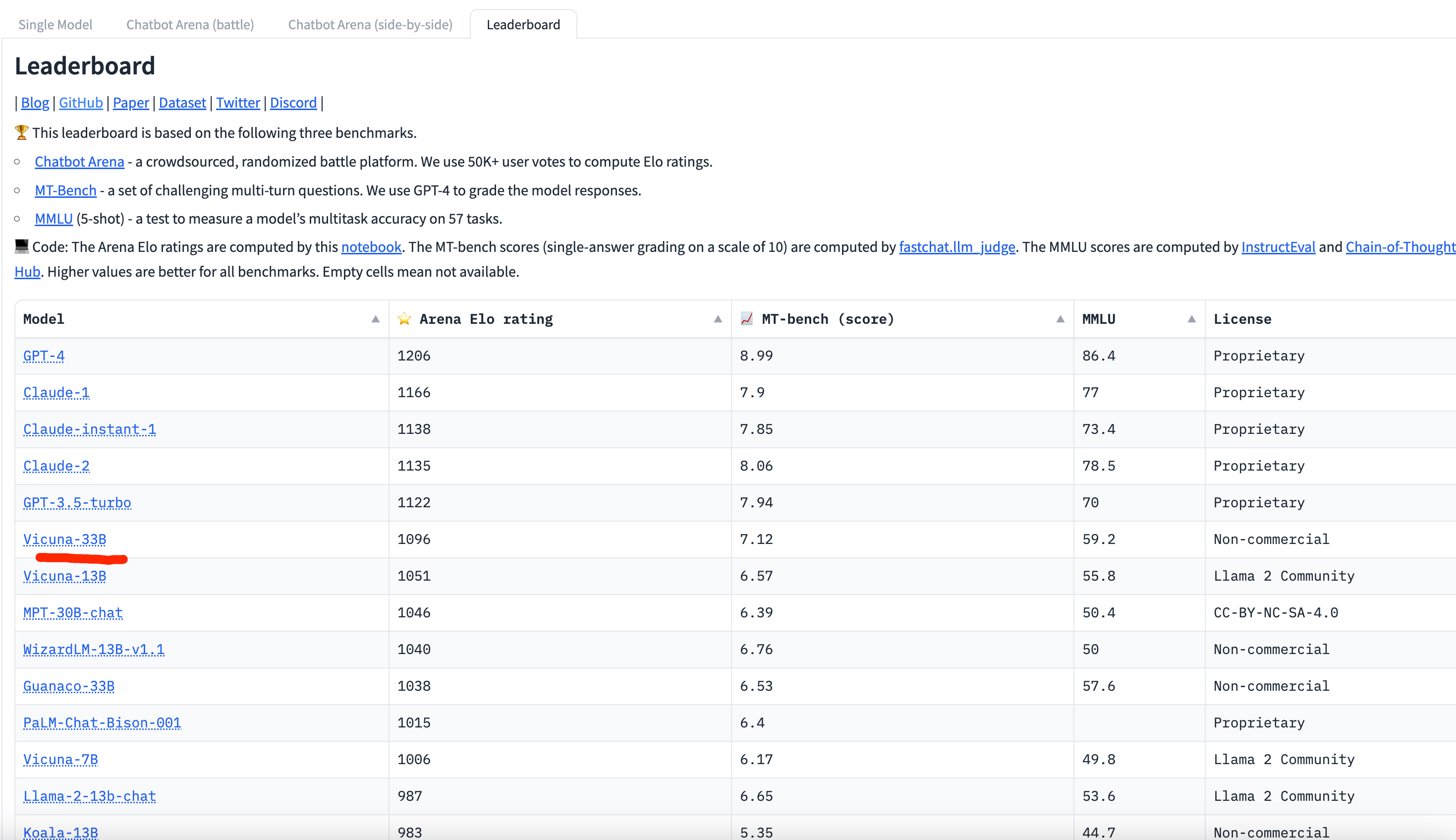
开源模型:智源悟道·天鹰 Aquila 大语言模型系列已经全面升级到 Aquila2,并且增加了 340 亿参数 Aquila2-34B。该模型在代码生成、考试、理解、推理、语言四个维度的多项评测基准登顶。智源不仅开源 Aquila2 模型系列,还同步开源了 Aquila2 的训练算法,包括 FlagScale 框架和 FlagAttention 算子集,以及语义向量模型 BGE 新版本。(github|新智元)
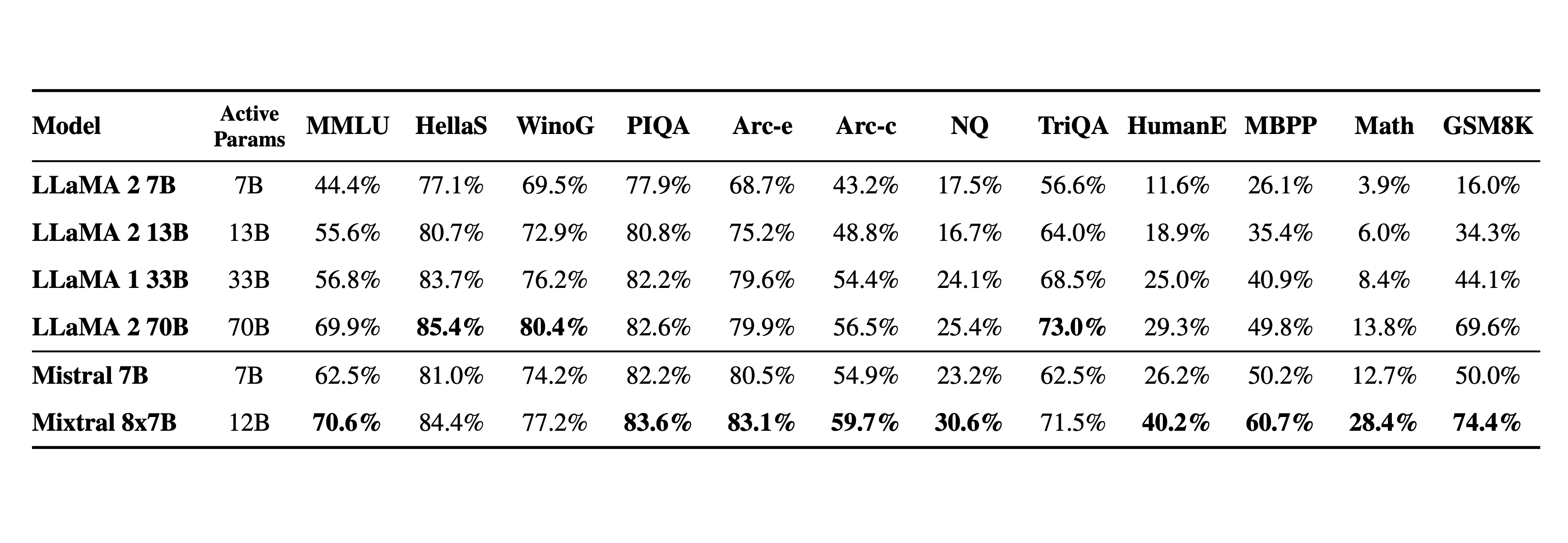
开源模型:法国人工智能初创公司 Mistral AI 发布开源模型 Mistral 7B,在每个基准测试中,都优于 Llama 2 13B,在代码、数学和推理方面优于 LLaMA 1 34B。Mistral 7B 使用 Apache 2.0 许可发布,这是一种高度宽松的方案,除归属之外,对使用或复制没有任何限制。(huggingface|机器之心)
多模态:今年 4 月,威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学研究者共同发布了 LLaVA(Large Language and Vision Assistant)。LLaVA 使用小的多模态指令数据集训练,但在一些样本上展示了与 GPT-4 非常相似的推理结果。如今,这一成果迎来升级:LLaVA-1.5,通过对原始 LLaVA 的简单修改,在 11 个基准上刷新了 SOTA。(机器之心|论文|Demo)
多模态:Meta 发布多模态版 Llama2 AnyMAL(Any-Modality Augmented Language Model),可理解不同模态输入内容(文本、图像、视频、音频、IMU 运动传感器数据),并生成文本响应。该模型在 VQAv2 提高了 7.0% 的相对准确率,在零误差 COCO 图像字幕上提高了 8.4% 的 CIDEr,在 AudioCaps 上提高了 14.5% 的 CIDEr,创造了新的 SOTA。(机器之心|论文)
知识更新:谷歌、马萨诸塞大学阿默斯特分校、OpenAI 研究者创建新基准「FRESHQA」,用于评估现有 LLM 生成内容的事实性。FRESHQA 包含 600 个自然问题,分为四大类(不会变化、缓慢变化、迅速变化、虚假预设)。这些问题要求模型「理解」世界上的最新知识,才能正确回答。由于其特性,FRESHQA 一些 ground-truth 答案可能会随着时间的推移而改变。(机器之心|论文)
多模态:加州大学圣克鲁兹分校研究团队提出 MiniGPT-5,一种以 「生成式 voken」概念为基础的交错视觉语言生成技术。除了多模态理解和文本生成能力外,MiniGPT5 还能提供合理、连贯的多模态输出。(机器之心|论文|项目)
图像补全:谷歌、康奈尔提出真实的图像补全技术 RealFill(Authentic Image Completion),可以用少量的场景参考图像进行个性化设置,而这些参考图像无须与目标图像对齐,甚至可以在视角、光线条件、相机光圈或图像风格等方面有极大的差异。一旦完成个性化设置,RealFill 就能够以忠实于原始场景的方式,用视觉上引人入胜的内容来补全目标图像。(机器之心|论文|项目)
图像生成:Adobe AIGC 生图平台 Firefly 最近升级为 Firefly 2,提升了图像质量、引入了矢量图生成功能,并增加了多项新功能。
上下文:MIT、港中文提出 LongLoRA ,一种有效的微调方法,以有限的计算成本扩展预训练大型语言模型上下文大小。在单台 8 x A100 设备上,LongLoRA 可将 LLaMA2 7B 从 4k 上下文扩展到 100k。(机器之心|论文|项目)
推荐上下文:MIT、Meta AI、CMU 研究者提出「StreamingLLM」方法,使语言模型能处理更长的上下文。StreamingLLM 的工作原理是识别并保存模型固有的「注意力池」(attention sinks)锚定其推理的初始 token。结合最近 token 的滚动缓存,StreamingLLM 的推理速度提高了 22 倍,而不需要牺牲准确性。(机器之心|论文|项目)
上下文:清华叉院助理教授杨植麟创业AI公司月之暗面(Moonshot AI)推出首款大模型产品智能助手 Kimi Chat。模型为千亿参数规模,支持输入长文本达 20 万字。作为对比,Claude 支持最大长文本为 100k(约 8 万字),而 GPT-4 则是 32k(约 2.5 万字)。(36Kr)
紧凑模型:AIGC 独角兽 Stability AI 宣布推出 Stable LM 3B 实验版本,这是一款专为便携移动设备设计的紧凑型语言模型,包含 30 亿参数,使用 256 个英伟达A100 40GB GPU 训练而成,主打文本生成。据介绍,与上一次发布的 Stable LM 相似,Stable LM 3B 的主要优势之一是体积更小、效率更高。此外,它的性能超过了目前最先进的 3B 参数语言模型,甚至超过了一些 7B 参数规模的最佳开源语言模型。(智东西)
- 算力
芯片:近日,清华大学集成电路学院吴华强教授、高滨副教授基于存算一体计算范式,在支持片上学习的忆阻器存算一体芯片领域取得重大突破,研究成果已发表于最新一期 Science。据清华大学介绍,记忆电阻器(Memristor)是继电阻、电容、电感之后的第四种电路基本元件。它可以在断电之后,仍能「记忆」通过的电荷,可成为新型纳米电子突触器件。(机器之心|论文)
芯片:外媒 The Information 称,微软计划在下个月举行的年度开发者大会上,推出首款人工智能芯片。同时,OpenAI 也在招聘能够帮助其评估和设计 AI 硬件的人员。(新智元|The Information)
- 应用
推荐审稿:斯坦福研究者尝试让 GPT-4 评审了数千篇 Nature、ICLR 顶会,与人类审稿人给出的意见相比较,并收集论文作者对评审意见的看法。研发表明,GPT-4 给出的意见中,超 50% 和至少一名人类审稿人一致。并且超过 82.4% 的作者表示,GPT-4 给出的意见相当有帮助。(新智元|论文)
有声读物:微软 MIT 等机构用 AI 将古腾堡计划的电子书转录为语音书,免费向公众开放,而且用户还可以用自己的声音来进行配音。任何用户都可以通过 Spotify、Apple Podcasts、Google Podcasts 等 5 个平台,免费获取到生成的语音书。古腾堡计划是全球最大的开源电子书库,目前书库中包含超过70000本已经进入共有领域的电子书。(新智元|论文|项目)
监控:据日本共同社报道,日本警方将首度使用 AI 技术来识别社交媒体帖子,监测抢劫、欺诈等犯罪行为。日本警方委托网络巡逻中心进行在线监控工作,利用自然语言处理技术寻找特定的关键词,并根据上下文识别涉嫌包含有害信息的帖子,然后将把收集到的数据报告给另一个外部组织互联网热线中心,互联网热线中心可以要求网站运营商和互联网服务提供商删除其认为非法或有害的帖子。(智东西)
英语学习:网易有道推出虚拟人口语教练 Hi Echo。用户可在微信小程序或应用市场搜索“Hi Echo”体验。据介绍,Hi Echo 搭载有道自研子曰教育大模型,是全球首个通过虚拟人形象与用户真实互动并帮助用户提升英语口语能力的产品。Hi Echo 覆盖 8 种对话场景和 68 个话题,支持自由对话,从发音、语法两个维度给出口语打分,提供语法改错、地道用词、语言风格润色等优化建议。(智东西)
- 其他
提示词:清华大学、微软研究院和东北大学研究者基于进化算法思想,提出了一种离散提示词(Discrete Prompt)调优框架 EvoPrompt。基于几个初始提示,研究人员利用 LLM 模仿进化算子生成新的候选提示,并保留在开发集上性能更好的提示,通过多次迭代提高提示词的质量。相比与手动设计、以前的自动提示生成方法。EvoPrompt 能持续获得更好的提示词。(新智元)
对齐:天津大学熊德意教授团队发布了大语言模型对齐技术的综述论文,全文共 76 页,覆盖 300 余篇参考文献,从 AI 对齐的角度对大语言模型对齐的相关技术进行了全面概述。(机器之心|论文|参考文献)
投资:据科技新闻网站 The Information 报道,在宣布亚马逊 40 亿美元投资后不久,人工智能初创公司 Anthropic 正在就 20 亿美元融资进行早期谈判,潜在投资者包括谷歌。(机器之心|The Information)
投资:全球生成式 AI 过去五年投资共计超过 220 亿美元(2023 年已达 150 亿),其中 89% 流向美国。(新智元)
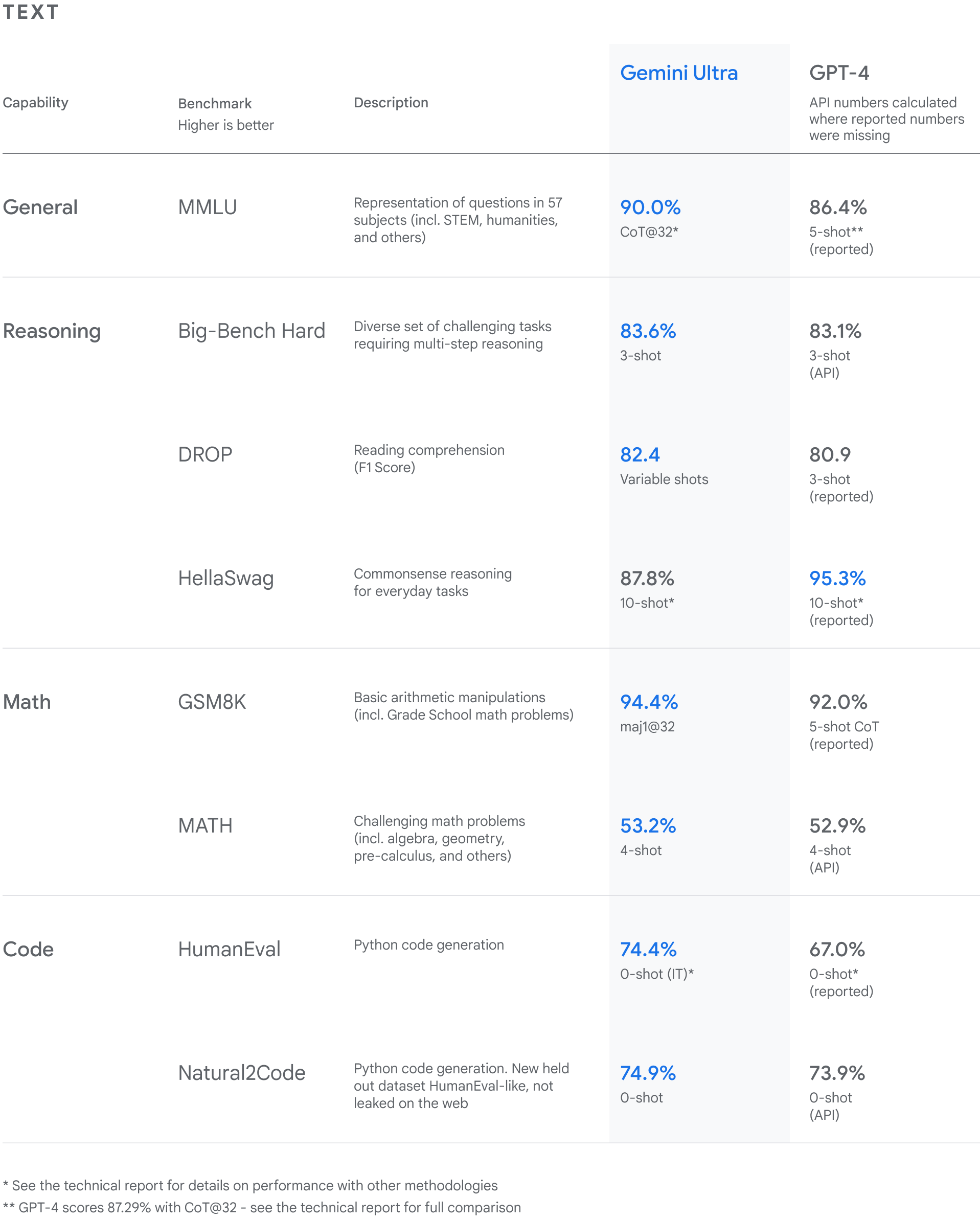
推荐技术报告:微软发布 166 页长篇报告,定性探讨 GPT-4V 的功能和使用情况。报道和原报告都很长,感兴趣同学请自行参考。(机器之心|报告)
推荐技术报告:近日,OpenAI 放出了 DALL·E 3 的 22 页技术报告,并讲解了其安全功能。除模型层改进,DALL·E 3 还增加了以下措施:
ChatGPT拒绝:ChatGPT 针对敏感内容和话题会拒绝生成图片提示。
提示输入分类器:分类器用于识别 ChatGPT 与用户之间可能违反使用政策的信息,违规提示将被拒绝。
屏蔽列表:在DALL·E 2 工作基础上、主动风险发现,以及早期用户的反馈结果,OpenAI 不断更新维护屏蔽列表。
提示改写:ChatGPT 会改写提示,包括删除公众人物的名字、将人物与特定属性联系起来,以及以通用方式书写品牌。
图像输出分类器:OpenAI 开发了图像分类器,可对 DALL·E 3 生成的图像进行分类,如果这些分类器被激活,可能会在输出之前阻止图像。(新智元|报告)
观点:MIT 研究者认为,大模型可以理解时间、空间等维度,可以被视为「世界模型」。在空间表征上,研究者对世界各地数以万计的城市、地区和自然地标的名称运行了 Llama-2 模型。他们在最后的 token 激活时训练了线性探测器,然后发现:Llama-2 可以预测每个地方真实纬度和经度。(新智元|论文)
观点:DeepMind 联合创始人 Mustafa Suleyman 接受 MIT 科技评论线上专访并抛出观点。“现阶段的生成式 AI 只是一个技术阶段,接下来会进入交互式 AI 的时代:AI 将会成为能够根据每个用户的不同任务需求去调用其他软件和人来完成工作的机器人。”在 Suleyman 看来,AI 的第一波浪潮是分类,之后是生成,再后为交互。(新智元|原文)
教育:国际 AI 顶会 AAAI 于官网宣布举办 AAAI 2024 全球大模型数学推理竞赛,由学而思牵头,谷歌、暨南大学等联合发起,邀请全球人工智能专家、开发者以及爱好者一起用大模型解答 K-12 中小学数学难题。比赛分为中文数学解题、英文数学解题两个方向,由学而思提供比赛所用的中英文数据集 TAL-SAQ7K-CN、TAL-SAQ6K-EN,主办方提供了 3 个作为参考的测评基准:GPT-3.5、GPT-4、好未来自研数学大模型 MathGPT。在比赛期间,参赛者需使用大模型对给定的数学题目生成推理步骤、答案,主办方将通过对比参赛模型输出答案与正确答案之间的准确率,来进行排名。(智东西)
二、其他
推荐谷歌 DeepMind 联合 33 家机构推出了机器人具身智能 Open X-Embodiment 数据集,并发布基于此数据集训练出的 RT-X 模型。该数据集从 22 个机器人实例中收集数据,涵盖超过 100 万个片段,展示了机器人 500 多项技能和在 150,000 项任务上的表现,是当前最全面的机器人数据集,有望解决机器人具身智能研究数据不足的问题。(机器之心|论文|项目|DeepMind)
树莓派 5 (Raspberry Pi 5)发布,相比前代全面升级,算力提升 2.5 倍,支持 PCIe、主动散热。售价也有对应提升,4GB 型号 60 美元,8GB 80 美元。(机器之心)
推荐迪士尼在 IROS 发布“生动”机器人。该机器人基于强化学习,与大部分机器人不同,迪士尼机器人专注于富有情感的的、可爱的姿态和动作。迪士尼研究科学家Morgan Pope表示:“大多数机器人科学家都专注于让他们的双足机器人能够可靠地行走。但在迪士尼,这远远不够。我们的机器人需要走得有模有样、会跳跃、小跑或漫游,以传达我们需要的情感。”(新智元(有视频)|IEEE Spectrum)
Hinton 加入 AI 机器人初创公司 Vayu Robotics 咨询委员会,帮助开发 AI 机器人解决方案。Vayu Robotics 正在设计用于本地送货的轻便低速机器人,这些机器人的动能仅为时速50英里汽车的1%,而且停车距离更短,因此更容易确保安全。据介绍,Vayu 致力于打造一个基础模型,来为大规模自主移动机器人提供动力。(新智元)